

This is the last blog post in the series about the first trembling steps towards Our Methods and in today’s blog post we have the summary of this series.
Summary
When putting everything together we can in the light of our set of principles and their implications , as well as common sense about transformations, understand why we from the beginning in the church and military started with silo organisations, as well as the understanding why we added projects in the 1950s. See this series of blog posts for the details about the history of organisations and the market and also this series of blog posts about human science.
In the same way, we can understand why silo organisations with projects on a slow static market worked with Technology Push, but Consumer Pull with non-solved complexity and high uncertainty of customer needs made it difficult for software projects. This are the main reasons to why software projects had much higher failure rate than hardware projects, where the details can be found in this blog post.
We also have the market of today that, in many cases but not all, requires speed, flexibility and has more complexity when we are solving our products. What we can then see in the light of our set of principles, is that the biggest problem in big silo organisations of today, is the understanding of how to solve complexity and avoid hampering the interactions in the category of the principles that regards the integration of the product. This is especially valid for organisations that bought all their software systems in the past, but now are developing this customer service themselves. This is valid for finance, banks, insurance companies and governments among others, which are changing their context from a Clear to a Complex one. All organisations going from buying software to develop it themselves are also vulnerable for accepting methods and frameworks that are not appropriate for development of big systems. Solving complexity means that we need to experiment with multiple and contrary concepts to fast get new knowledge and see if there is a solution or not for any of the concepts, or to systems design the system into parts. It is very important to understand that it is impossible to predict the result of the feedback loops in the Complex domain in advance, so the feedback loops need to be as fast as possible. This means no false cadence (yes, it is false, since cadence means overlap) with fixed time boxes, is possible at all, since it is hampering how fast we can be. The integration mentioned above, is valid after the systems design, which means that the actual solving of the activities and their interdependencies, and putting the product together, are difficult and time-consuming if the needed interactions are hampered and T-shape possibilities are low. This in turn will give us only aggregation possibilities, not the needed integration. At the Integration Events – IEs – the parts are integrated to something bigger and systems tests are done on the wholeness, the whole system product, where the time to the next IE is context dependent. The more obvious it is, the surer we will be that we will be successful, which means that the time until the next IE can be longer, since small activities only means unnecessary starts and stops. But, remember that it always depends on context with the need of always being flexible, so for product development regarding hardware, false cadence in any form can severely slow down the flow.
We can also understand that KPIs, control and measurements on silos, or parts of the silos, leads to egoistic parts and indirectly also is a disrespect of our people with many unsolved problems left untouched. This inevitably leads to sub-optimisation, making it impossible to handle complexity and also even more hampering the integration and the need of free interactions to solve the problems of product development. Too much measuring on the silos or their parts, easily leads to a culture where no one wants or dare to take risks and make faults. This will hamper innovations, since they have a high need of experimentation for gaining new knowledge, which is neither possible to control nor measure.
For example, the Lean Product Development methodology takes care very well of our organizational principles for product development, even though its focus has been on hardware, where the difference to software actually is small. And if we are looking at the principles Toyota is leaning on, there is no difference at all. In Lean product development complexity is handled by Set-based design, multiple concepts and platforms to solve complexity with low risk and by nourishing full-time resources, T-shape (also end to end) and short chains of interactions* for the actual work. This shows a method that follows our set of principles to a very high degree, where the details can be found in this blog post. We can then also understand why Toyota has been so successful, since they cannot only make new easy-producible car models on their platform very fast, they can also produce them fast and with high quality with their Lean Production methodology, which follows our set of principles to an even higher degree, where the details can be found in this blog post.
The HBR article “The New New Product Development Game” [1] is also showing other Japanese organisations that follows our set of principles to a very high degree as well, also here with plenty of new innovations in the stated projects, where the details can be found in this series of blog posts.
As stated earlier regarding the teams, they can be any x-shape, but to take care of wholeness on the levels higher than the lowest, there must be not only a transdisciplinary setup to be able to cover all disciplines, but also to be able to have the best prerequisites for doing innovations and make platforms with modules taking care of the whole, when needed.
Note! Frameworks for scaled agile most of the times do not have the Big Picture. Apparently, they know about this since they first start to implement the parts (value streams), hiding as long as possible this fact. And the reason why it is possible for the framework to get away with no control of the Big Picture, is because the part of the old organisation that have control of the Big Picture normally is top management, which are not only the last ones to be transformed, they are also the ones with least understanding of the way of working, both the current one and the new one transformed to.
As we have seen through the history, we can understand the evolution of the organisations, the silo organisations and their projects are perfect for slow Technology Push, but not for Customer Pull when the complexity is within the projects. From this we can also understand the hundreds of different methods trying to take care of silo organisations that did not work especially in silo organisations that did not respect their people, but of course also due to KPIs making the silos egoistic. We can therefore also understand why the Agile movement for software development started, since the methods did not work out as expected, mostly failing.
With our set of principles, we can easily see why the methods were failing, since most of them are violating at least a few principles. This is also brought up in this series of blog posts examining many famous methods that Dr. Russell Ackoff believed were antisystemic (suboptimizing) [2], which also regards Continuous Improvement** done on organisations as he stated. Silo organisations with KPIs, suboptimize on the people side and the agile organisations ignore the planning effort needed on the activity side of our system start definition “People that interact to solve activities with interdependencies for a common purpose.”, and frameworks that are scaling agile many times sadly on both sides. And when we on this sub-optimisation also add disrespect of people, an organisation is in deep trouble. Trying to do Continuous Improvement** on parts (any direction) of organisations that are already sub-optimising, will severely deepen the problems instead of do any use.
But, with our set of principles, their implications and from this series we now know how we can set up Our Method for product development (mostly) on a high level, where we also can see examples of different product development problems that can be actual depending on domain in this blog post. We can now make successful organisations from scratch, or change any organisation to the better, since we with the Prefilled Problem Picture Analysis Map can find the root causes to any organisational problem, as well as fix the problems.
Here is Our Method for product development (mostly, but still general to some extent) on a high level as a picture and as pdf, Our Method for product development ver 0_97.
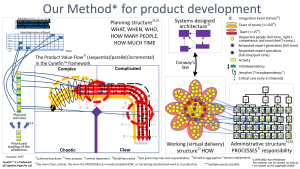
And here is our total organisation definition for product development again, covering the WHAT for all different contexts:
Respected people with a common vocabulary, working full-time in a flat hierarchy of teams founded on the numbers 5, 15 and 150, also in the light of Conway’s law, with the right specialist competence, and understanding the Cynefin™ framework and Conway’s law, that in parallel if needed, interact freely and end to end over the whole organisation in as short chains of interactions as possible, giving them the necessary broad competence to directly take care of organisational problems as well as do continual improvements, and therefore be able, to efficiently and effectively solve product problems, by first exploring to gain new knowledge, activities with interdependencies, fully planned and under control, to be able to build the system product or service, incrementally if possible, always with the appropriate architecture under control and responsibility and always with timely Integration Events and Aggregation Points depending on context, to get just-in-time feedback, where also the long-term critical line, activities, interdependencies, Integration Events and Aggregation Points are fully under control, and visualised as well.
We have not talked so much about a method for production, but here is one that of course also are following Our set of principles, which as we can see is much easier, since many of the principles never are “activated” in the Obvious domain of the Cynefin™ framework, where we have the production line. Remember though that with less science to fulfil, the solution space will increase, which makes the number of possible solutions very big. Here is the picture for production and as pdf, Our Method for production version 0_97:

What can be seen when comparing production with product development is three vital issues where production, as in a Clear context, has limitations and that regards; limited to only aggregation, limited to only solving activities and Kaizen, but not problems***, and limited to have low or no flexibility to take care about changes in the product itself or environment (more than changes regarding the production volumes). All these three issues, product development need to be able to handle, which can be seen in the prior picture. This means that Agile organisations at scale need to be vigilant, since Agile development had its starting point in Lean Production, with the obvious and high risk of the way of working not being fit for purpose, for any of these three issues, especially when scaling up.
What also can be seen in the picture is that the organisational solution in production is a Functional organisation, which is also the normal recommendation and the most common solution for production companies.
If we make an organisation definition only taking the production context into consideration, it will look something like this, a much easier and shorter than the total definition:
Respected people with the right specialist competence, working full-time in teams built on the numbers 5 and 15, that within the teams interact to efficiently solve activities with no interdependencies, fully long-term planned and under control within the team, and that together with the other teams repetitively build the system product linearly, always with timely Aggregation Points, to get fast feedback, always visualised.
When we look at the differences between our total organisation definition and the organisation definition for production, we can clearly see the problems that software development using Agile has, since it started from the methods and tools within Lean production. Especially obvious it is regarding scaling that in product development is not aggregative, see this blog post for a deep dive about scaling problems within organisations.
From the product development method above, we can also easily make one for a service organisation, that will probably be something closer to production than product development. This can be done by removing parts that are not valid for a service context, but of course we can generate a method from any other domain and context. Try yourself, it is much easier than you think, since it to a great extent is common sense, see this series of blog posts about common sense for a further exploration.
This was all for this series, c u soon again.
Next “chapter” according to the reading proposal tree is the wrap-up blog post of the whole System Collaboration Blog Book, but first the branch about problem-solving, symptoms and root causes should have been read, where the series of blog posts about how to boost your problem-solving ability is first.
*bottom-up preparations built on trust are made for decisions, to make the long chains of interactions in the line hierarchy regarding decisions less calendar time consuming, see also this blog post by Dave Snowden about trust being earned and cannot be pre-designed into a method.
**remember that on the whole only continually improvements can be done, due to the synchronisation needed between the parts when the respective part’s improvements are executed at the same time, for example takt time change. The parts can (and must) themselves be continuously improved, as long as they do not affect another part.
***at production problems, of course issues that is handled temporarily to not stop the production, will be solved outside the production line and can be problems in the Complicated domain, or even in the Complex domain, see this blog post for the details about Lean Production’s high flow efficiency.
References:
[1] Takeuchi, Hirotaka and Nonaka, Ikujiro, ”The New New Product Development Game”. Harvard Business Review, Jan 1986 issue.
Link copied 2018-09-05:
https://hbr.org/1986/01/the-new-new-product-development-game
[2] Ackoff, Dr. Russell Lincoln. Speech. “Systems-Based Improvement, Pt 1.”, Lecture given at the College of Business Administration at the University of Cincinnati on May 2, 1995.
The list at 03:30 min, the national surveys at 03:40, and the explanation at 04:48 min. Link copied 2018-10-27.
https://www.youtube.com/watch?v=_pcuzRq-rDU