

In organisations, as mentioned in the first blog post of this series, we have two different kinds of Organisational Clogging. We have the clogging of people and also the clogging of the activities to be solved, and in these two blog posts, about the too many people and too many queues of activities symptoms, there is more information about details. There are actually two more symptoms regarding people and activities that will be brought up later in this series, to complete the symptoms from Organisational Clogging.
Here is how it looks in the Prefilled Problem Picture Analysis Map so far, when we put the pictures from earlier blog posts all together, so we get the whole chain of symptoms for the Organisational Clogging symptom.
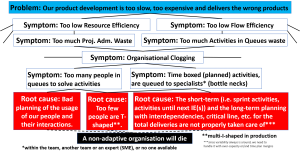
Remember also that people and activities are important, since they are the beginning and the end our start organisation definition, “People that interact to solve activities with interdependencies” respectively, see this blog post for information about the start and our total organisation definition.
The main reason for the clogging of people are, if we go down to the root causes, too many part time people working and their interactions and that too few are T-shaped. For clogging of activities, we have unplanned activities with interdependencies linking all teams and experts together and that too few are T-shaped as well.
So, in knowledge work we are integrating the work, not aggregating like in production, see the blog post Aggregation vs Integration, for a deeper analysis. The discussion of car congestions in the last blog post, is therefore definitely not for product development, and instead more an example that can be used for production, but it should be used with care also there, since it more represents mass production, then Lean Production itself.
And as you already have understood from earlier blog posts, the traditional silo organisations with projects and Agile development organisations clog their organisations differently.
The traditional silo organisations with projects are taking care of the system product’s architecture and the structure of the work in a good way, but have great difficulties with the clogging of people. The negative effects of too specialised employees, that we discussed in this blog post, makes it hard to solve the projects smoothly, with a lot of waste as follow.
The clogging of too many people must be paid attention to in our silo organisations, since our habit if there are too many people coming to the meeting, is just to book a bigger conference room. But, we already know our 5 and 15 numbers, see the blog post series about Human science, so we really should not make the meetings too big, and instead ask ourselves why we need so big meetings. And with all interactions that are exponentially increased by the more people we add to a meeting, the harder it will be to get something out of the meeting or difficulties to take a decision.
Recently we have also discussed low Resource Efficiency, in this blog post about Project Administration Waste, which we get when we use too many people in our projects, but when actually fewer people can solve the task. If we also at the same time use part time resources, we will also get Activities in queues waste, many and long Mean queues that decrease also our Flow Efficiency.
As opposite to silo organisations, Agile development organisations are good taking care of their people, but instead lacking the planning part, which easily give us Mean Queues. We have already thoroughly elaborated on queues symptoms here, and that is the reason of clogging of activities in Agile development. Because, when activities with interdependencies between teams and experts are not planned, the activities cannot be solved, and the activities are instead clogging the organisation, which of course decreases the Flow Efficiency.
In the next blog post, we are going to look into the marvellous anti-clogging-systems that ants have and also wrap up this series. C u then.