

In today’s blog post we will elaborate on the problems of having queues in our organisation, and find their root causes. And we will do that with help of our Prefilled Problem Picture Analysis Map, which it is now time to start to fill in. Here is the link to the presentation of it in an earlier blog post for newcomers or as a refreshment, The beauty of negating our principles to become root causes – The Prefilled Problem Picture Analysis Map.
Here is its empty structure, and here as the .pdf file, empty prefilled:
![]()
At the top we have our problem description “Our product development is too slow and expensive, delivers the wrong and too costly products with the wrong quality, made by unhealthy people.” in red, and at the bottom we have the dark truth; “A non-adaptive organization will die”, which means that the more of our green root causes we cannot solve, the harder we will have to be adaptive too the market. And if our organisation have many remaining root causes, i.e. does not fulfill most of our principles, our organisation cannot survive. The green boxes we will from now on, in this, and coming blog posts, fill in with our negated principles, that then become our root causes. The white boxes will be filled with the many symptoms that are commonly found within any organisation.
Now we are going to start to ask multiple why. To our why questions, there are often multiple answers (symptoms), but today we only concentrate on the chain of symptoms that passes the queue symptom, and finally ends up in root cause(s). To begin with the chain of symptoms for finding the queue symptom is a good start point, since we definitely not need a lot of activities to be queued up in our organisation, since that means lousy Flow Efficiency.
Our start problem description is this picture.
![]()
Asking why, will give us the following symptom to add to our chain of symptoms:

Asking why again, will give us also the following symptom in our chain of symptoms:

And here we have the Activities in Queues waste, that we talked about earlier in this blog post. Asking why again, will give us also the following symptom in our chain of symptoms:

And now we have found the queue symptom, our Mean Queues, we were looking for (the empty box is not important now, and will be explained in a later blog post). Our queue symptom has two variables to play with, and that is people and activities. And as you remember from earlier blog posts ,for example, Our total organisation definition for a flourishing organisation, we have our start organisation definition “People that interact, to solve activities with interdependencies to achieve the purpose**.”, so now we are close to the root causes, our negated principles. And since these variables represent the left part with people and the right part with activities of our definition, we must ask why at least two times, since it will be not less than two root causes.
See also this blog post for a deep dive into the different kind of queue problems, for example bad planning, that we can have. A special attention need to be put on the too low understanding of the reason for variability***, not the variability science or queues sinces themselves. The discussions in Agile software development about queues and variability, have really gone the wrong way with a deep dive into science, still trying to solve the impossible symptoms, which means guessing without knowing (“killgissa” in Swedish), rather than dissolving the root causes.
This will finally give us also the root causes for this chain of symptoms:
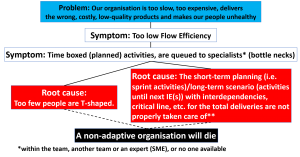
As you can see, in this case, this chain ended up in two root causes, two of our negated principles for a flourishing organisation. So, if we have queues in our organisation, we need to look into both these root causes and do our best to solve them. And no one of the root causes requires some magic to happen, only hard work and determination that they need to be fixed. But, if we instead try to fix the queue symptom directly, then the hocus-pocus will never stop, that we can be sure of. Because, then we can never ever get control of what we are doing, because we are sub-optimising our own organisation, by trying to optimise its parts. This also means that if we are stating solutions to symptoms as principles, we will have an endless list of principles, since the original symptom generates endless chains of symptoms. If we not understand this fundamental basic knowledge that a symptom can neither be solved, nor “principleized” to become a principle, we will easily fail. We will also easily become victims of snake oils, which Dave Snowden at Cognitive Edge many times in his blog posts have called methods and frameworks that have no scientific proof. Here is one of them where he have made a list of snake oils [1].
Queues are a big problem in Agile product development, since the focus on reducing Flow Efficiency waste by directly trying to reduce the queues, is only leading to sub-optimising, see this blog post about WIP Limits. Another commonly proposed approach for Agile product development to decrease the queues, is to reduce batch size, which if we take the car congestion as example, is clearly wrong in that case. This because the cars come independently in batches of only one car, see this blog post for more information. The same goes for queues of activities on the different columns in the Kanban board, which can only be dissolved together with our root causes above. To blame the batch size, activity size in this case, to be too big and therefore will create queues, will never compensate for bad T-shape and/or bad planning within a team, or between the teams and common experts. Remember that the timebox size is already decreased to only two weeks for a sprint in many Scrum implementations, which is shorter than any other way of working has, and still the other way of workings do not have the same magnitude of queueing problems****. Also the story size within the time box is shrinking, and the story of the shrinking stories in Agile product development will be brought up in a later blog post. The reason is that in the original thinking by Kent Beck in his first edition of his book “Extreme Programming Explained” was that a user story was “estimable between one to five ideal programming weeks.” [2], which is now reduced to only 1-3 days (average 2 days).
If we instead look at traditional waterfall of working, it has also taken care of the time planning root cause well, in the same way with margins in the time plans. How the margins are taken care of will be discussed separately in a coming blog post, about the needed avoidance of accumulation of variability margins. And the T-Shape root cause has been successful taken care of for different areas within a silo. But, when going into parallel work and the need of T-Shape fully inside the silos, between the silos and cross-functional over all silos, the T-Shaped root cause need to be handled. If this root cause is not handled, parallel work is not possible, and this has been the clog for silo organisations the last decades.
How Lean Production and Lean Product Development take care of these root causes, will be brought up in the series of blog posts regarding Organisational Clogging, for Lean Production here, and for Lean Product Development here.
Now we are well prepared for looking into Agile’s WIP Limits, which will be tomorrow’s blog post. That will for sure be a rumbling blog post, because the question is if the root causes really have been considered. C u then.
Next “chapter” according to the reading proposal tree is the blog post about finding the root causes to too many people in the projects.
*within the team, another team or an expert (SME), or no one available
**With organizational purpose means; manufacture a product, service, develop a new product, etc., with a certain price and quality. We are not talking about the nowadays popular Purpose statement, that is only a continuation of the easy-gamed value and mission statements. In this kind of statements, behaviour, properties and core values of our employees are stated, which is more of wishful thinking, since they will only emerge from multiple interactions within the organization. Since the interactions in turn, also emerge from our way of working, one can believe that if the purpose of the organization is not fulfilled, neither will the emergent behaviour and properties of our organization be what one could wish for.
***since variability always is around, we need to handle it with over-capacity or/and time plan margins
****of course queues to for example specialists, CM, release management, Integration & Verification, etc. need to be handled with over capacity, or by margins when doing the planning, all due to variability.
References:
[1] Snowden, Dave. Blog post. Link copied 2019-08-25.
https://cognitive-edge.com/blog/a-curmudgeonly-christmas-a-critical-new-year/
[2] Patton, Jeff. Blog post. Link copied 2019-01-23.
https://www.jpattonassociates.com/kanban_oversimplified/