

Today we will continue with Agile development and its T-shaped teams in the perspective of sequential and parallel work.
In short (but, of course there are endless variants): A T-shaped agile team is normally working with stories within a sprint (iterative time box of constant size of 1-4 weeks). It is self-contained, which means that it can analyse, review, build and integrate & test stories. These stories, with an average about three days, but always less then the sprint length, are integrated with stories from other teams (Continuous Integration) in the total software into features, and the features are integrated into epics. The integration can be made by the same team, or by integration teams at the different levels, but is not of importance for us now.
It is important to understand that all knowledge work is integrated together to the total solution. If we believe that we can divide the total work into parts (at the same time as the architecture) and at the end just aggregate (really a false integration) all the solutions per part together, like in production with all their processes, then we for sure soon will have a crappy systems design, since it is non-existing. Because, we always need to do the analyse the system first and do a systems design, where we also make the architecture and at the end we integrate everything together to a unified whole, probably with prototypes. It is not possible to omit the systems design, it is essential for the development of any product. Aggregation, integration and false integration are handled in this blog post.
So, the sequence within the team is analyse, review, build and integrate & test the stories and then we have an integration on one or more levels, depending on the size of the total deliverable. We start to look into this for a team making stories during a sprint, and the length of the sprint, is not important for us now either, we only need the sequence.
For one story it will look like this.
![]()
Looks pretty much like waterfall, right, but it is of course no surprise since the walls go before the roof of the house, i.e. there is always an order to do work. So, with many stories within the sprint it can look like this (the time line goes from upstairs to downstairs before left to right, i.e. story per story).

If the team starts to analyse all stories together first, to get advantages if the stories are in the same area of the architecture, GUI, or others, it can look like this (analyse first, then story per story).
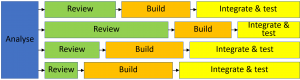
Or, even like this, if the team’s T-shaping journey is only in the beginning.

And this we have seen before, our Overlapping Concurrent Sequences, that is common when we have I-shaped teams. If we focus on the different disciplines instead, we will get Overlapping Concurrent Disciplines instead, and the picture then looks like this:

The last picture shows the big correlation to parallel work with I-shaped teams needed for fast work in traditional silo organisation that look like this:
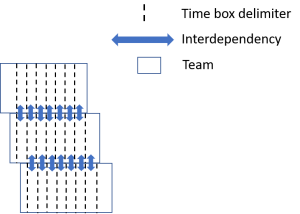
See this blog post for further information and also about the correlation to Lean Product Development, and the different way of working for achieving fast feedback loops.
Of course, the team can get blocked/delayed by; other teams’ late delivery, teams working in the same code area, violations of Conway’s law which has led to crappy systemisation, waiting on the same expert* as another team, team members that has nothing to do because they are not T-shaped enough, etc., which has not been considered above. This is a huge and neglected problem for Agile teams at scale, that is working in sprints, and is handled in this blog post.
So, for an Agile team, the sequence of analyse, review, build and integrate & test is of course always there, but since the team members will achieve more and more T-shape, it means that the team members are able to do more and more different tasks. This leads to an unlimited number of scenarios of the work inside the sprints.
The different pictures above are examples on how an Agile team can approach the stories within the sprint, and it is up to the team to decide, depending on the stories they have chosen, their T-shape, etc., how to work so their throughput of stories is as high as possible.
Warning! If a team only looks at its measure for Flow efficiency it can be treacherous. Because, a high flow value from a Process Cycle Efficiency measurement, unfortunately does not always correspond to a real high Flow Efficiency, and that pitfall is brought up in this blog post.
Even if the scenarios can look very different from one sprint to another, it is as stated above, still a sequence that need to be followed, which makes the difference to waterfall way of working small from that aspect.
Instead the big difference is the size of a time box, that often can be shorter in software product development, due to the fact that the there is no long lead times putting any constraints, like in hardware product development. This means faster feedback, and changes the start in the Cone of Uncertainty** to look something like this instead compared to a normal start of a big software development project using the waterfall way of working:

A sprint time box, as stated above, has the size of 1-4 weeks, but as stated before, the important synchronisation point is the Integration Event, and the time until the next Integration Event depends on the context. The time box size therefore needs to be appropriate so we can have just-in-time feedback, which mean that we need to be flexible according to the context we are working in.
Now, it is time to look into parallel I-shaped teams which leads to an increase of interdependencies, which we already have seen, which is the next blog post.
C u tomorrow.
*and as you understand: when many teams are started up at the same time, every two weeks (false cadence), especially the first sprint of an increment (normally 4-5 weeks), the needed sequence of the phases; analyse, review, build, integrate & test will of course make that the experts outside the teams, are needed by different team at the same time. This is an interdependency that we need to be proactive to, and plan for, instead of building Mean queues to the experts. The conclusion of this is that Kanban work is better between the Integration Events, to avoid having the work to start up frequently at the same time in sprints (with false cadence). But, this also means that the Kanban teams need to learn that they need to finish their tasks, and not build Means queues on their own Kanban board :-).
**see this blog post, for more information about the Cone of Uncertainty.