

Welcome to this blog post that will take a deep dive into the world of Requirements Traceability (RT) when system (product) development is the purpose of the organisation. This will in turn also give us the context, that in this case will be the Complex domain in the Cynefin™ Framework by Dave Snowden, where all product development is. In the blog post, system will be synonymous with any kind of product or service, for software, hardware or in a combination. But the main focus will be on RT for the software system development domain, so when it is not valid for hardware, it will be clearly stated. Added can also be that sometimes hardware production will be used for comparison. We will go through why we need RT in this context, what we need to do to get awesome RT, and the impediments organizations are facing today that directly or indirectly hindering them to achieve awesome RT.
Throughout this blog post, the term RT will be used, so it is not mixed up with the term traceability, that more and more is reduced to only be able to search and find artifacts with links or tags. RT is an important part for achieving any high-quality system, and is also tightly connected to Configuration Management (CM). Traceability on the other hand, is instead related to Content Management System (CMS), which we later will go through thoroughly.
RT in short means that we need to keep track of the initial ideas, via the requirements and the systems design, all the way down to the realisation of the system and the possibility to go backwards as well. We can clearly see that there will be levels of different kinds of artifacts, and we can also see the need of a top-down approach to keep track of these levels. RT is always important to consider regarding systems, especially big systems, due to their higher complexity, which in turn requires better overview, more structure and order. RT is even more important when a new system is developed from scratch. This yields both safety* and security* applications, where RT is a total necessity for the former. For the latter, the more security requirements the system have, for example legal, risk and compliance in bank systems, and that goes for any size of the system, the importance of the RT rises as well.
Important to add is that when we have the context, the need of RT is domain independent, since it is about the ability to trace the requirements, and not what the actually requirements are about, or their realization; hardware, software, bridges, buildings, etc.
It is also important to understand that the requirements on the RT always need to be independent on the way of working, so we are not easing these requirements, due to deficiencies in the way of working, for the actual context and domain. How we maintain these requirements, will of course be strongly dependent on the way of working. But here we need to be vigilant to effect talk and counterfactuals used by many methods and framework in the agile community, so we are resistant to easing the requirements. We need to make the work with RT a natural part of our daily work with our system, exactly in the same way as for other activities that also lead to high quality. And this we need to do from the beginning and contemporary as we introduce a new way of working, so we are not just adding on supplementary work. If we are successful with this, it will give the organization great benefits from the requirements on the RT. To have overview, structure and order is help for self-help, and the need of overview, structure and order becomes paramount when the system grows, otherwise we will not achieve the strength of RT and other quality work.
And here we need to be alert, since agile focus on the need of the customer (right product), making the overview, structure and order of our system (product right) to suffer, making the RT suffer as well, which in turn makes the quality suffer. We can understand that scaling of agile with bottom-up thinking will not lead to a RT that can fulfil our needs. We cannot focus too narrowly on that if we scale up agile, we will have the effect of better quality, just by making shorter implementation cycles/iterations, or just by proclaiming the motto built-in quality. If we swallow this contrafactual condition, we will automatically ease the requirements on the RT. As an effect, the risk is also very high that we would also remove system test, or remove necessary and earlier decided quality work, with reference to the promised effects.
The reason that we have this situation, is the fact that the agile way of working has its origins in small scale, a few teams that develops small software systems, small applications often with low security, making the complexity lower. This leads to that in small systems (hardware or software), faults can be found and corrected, despite the lack of RT. In software, structural faults or bugs, are corrected by refactoring [1], which original meaning in short, was to redesign and restructure, to better fulfil the non-functional requirements, but with preserved functionality. A few agile teams can be compared to a smaller organization, no matter domain, where much of the information is stored only in the heads of the employees, which makes the access to documentation low, especially the system documentation regarding the whole system. This is however possible, because we with the lower level of complexity, do not need to prioritize overview, structure and order, and therefore do not need to keep work with RT in focus. And with lower levels of documentation, only having the needed information in the heads of the employees instead, which will per se give us greater flexibility to make changes, since we do not need to update too much documentation. But, even in small systems, a low level of documentation, means low RT, which means increased risk taking. Refactoring frankly means trying to solve the symptoms we always will get, from an earlier neglected systems design, which is our root cause. Here we also need to be vigilant, since the small-scale agile way of working does not need RT, since refactoring can be done, does not mean that we can add RT when we want it. Rather it is the completely other way around, RT cannot be added without completely changing the concept of agile. Why? Because in agile there is no structured systems design, and the non-functional requirements are neglected as well, leading to that the complexity is not reduced. This means that the functional requirements will be incorrect and therefore in constant change, throughout the whole development until the product is ready. Adding RT to agile, will give a tremendous administrative work due to the constant change of the requirements, which will slow the agile processes down considerably.
Scaling up a way of working, always leads to higher complexity, since we need more teams to take care of the bigger tasks, since the system to develop is bigger. This leads to the need of a RT, since it is no longer enough with information in employees head can be presented orally for other employees. Instead, we to a high degree need requirements-, system-, verification and validation documentation already from start as well in the form of documentation. And as we stated above, if we add RT to agile, the concept of agile is lost, which makes the continued concept of agile unscalable, and not suitable for big software systems, since RT is a must, to not have unproportional big risks. Once again, we can see that for big software systems, the bottom-up strategy of false continuous integration (false since no systems design has been done) to achieve the system, will only lead to the impossible task of making the high-level system documentation and RT for big systems in hindsight. And copying the written code in production to produce the system documentation, will not help in order to understand the total system, and why it was done this way and not another way. The neglection of making a systems design, which in turn leads to an improper RT or lack of RT at all, is instead a top risk for not making the product right, and is for big systems never interchangeable with having flexibility to make the right product. This becomes even more obvious when looking at all aspects of achieving a flourishing way of working, see this series of articles about System Collaboration Deductions.
There are many areas to understand in order to achieve a RT with high standard; Information (communication and documented information), Metadata, Version control, Architecture (Product structure), Baselines, Requirements Traceability (deep-dive) and Configuration Management. There are also other areas like Tags and labels, that are more connected to CMS systems, but still helpful for faster searching, when specific information needs to be found. When we have all the details for the respective areas, we can finally deepen RT, the what, the why and why not do it in another way.
All these areas mentioned above will combined, give a high-class RT, that in turn will give our system a high quality. Let us now deep-dive into them one by one.
Information [4]
Information means knowledge that you get about someone or something and is commonly transmitted through discourse, writing, symbols, diagrams, pictures, etc., which we will focus on here, even though there are other levels that can transmit information, like buildings, rituals etc.
The picture below, information and its types, shows the two different types of information we have, in form of communication and documented information, and their respective content (artifacts).
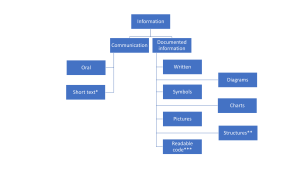
*Instead of oral discourse; SMS, chat, short email
**Architecture, line organization structure, virtual delivery structure, activity structure, etc.
***Readable code can also be commented for better understanding, and also includes necessary configuration files. The comments shall however only be seen as supporting text to this part of the solution, as when you write a supporting text to explain some of the other artifacts in Documented information, as charts, pictures or structures. Readable code differs from binary code (coded data). Binary code is an artifact that only computers can read, which also is the reason why binary code is not represented in the picture. For RT however, the binary code is very important, since we always need the trace from readable code to binary code and back, as one part of the total RT.
Communication
Communication [5] is a necessity for us humans and is often seen as a two-parts-process, where we exchange thoughts, opinions or other information of simpler character. Communication is therefore very important when it comes to transmit information between individuals, since we talk faster than we read, and in turn read faster than we write. Without communication, no collaboration, interplay or co-creation is possible, or at least extremely difficult. There are many impediments for successful communication. Two of them are excessive information, where for example a person gets too many concurrent messages, and too complex information.
To communication is commonly also referred electronic short written communication as a chat, SMS or short email, etc. This is an efficient type of communication when it comes to two-parts communication where the effect is easier problem or instructions, that with only a few iterations of information exchange, can reach an agreement. With all oral communication, intermediates need to be reduced. This so that the transmitted information as far as possible is not incomplete, interpreted or corrupted. The longer the chain is, the more of the original information is lost, where the children’s game Chinese Whisper is a good example.
Documented information
First of all, we need to have documentation [6] that shows ideas, requirements, system documentation that show how our system and its part fits and interacts together to a unified and well-functioning whole and finally detailed specifications of the parts of the system. But, as stated above, we need to beware that documentation and information nowadays are used interchangeably, even though the fact that documentation is a subset of information. To avoid this problem, ISO 9000:215, which points out the necessity of having good RT through the whole life cycle of our system, has introduced the term documented information [7].
Documented information is material used to describe, explain or instruct something and also its parts, and should be easy to read and understand. This something can for example be an object, system or procedure, and documented information can cover the integration, installation, maintenance or use of it, or its parts. To make documented information involves sketch, style, presentation, review, approval, distribution, update, traceability, etc., and can also be to create completely new material.
Why documented information?
Documented information is used by us humans in order to bridge our own limitations of how much information or/and how complex problems we can solve, when the complexity increases, as described above. This means that we need documented information, since we cannot with only communication, transmit the information to other people or solve a complex problem together with other people (or even by ourself). Documented information is a combination of writing, pictures, charts, diagrams, structure, simply what is needed to make the documented information as comprehensible as possible. A mix of the former (writing) and the latter ones, often gives the best result, to be able to solve a complex problem, or describe something that is complicated. Structures in form of architecture, activity structure and line organization structure has been used by us humans for thousands of years. They are all a result of the need of reducing the complexity when we have too much information for us to handle, or the problem is too complex to solve. To the structures can also be added the virtual deliver structure, that is not more than 70 years, and added to avoid sub-optimization. It was introduced together with projects, but is totally independent of way of working, traditional waterfall, Lean product development or Agile at scale, and is always a necessity in order to avoid sub-optimization in product development of especially big systems. As we can understand, documented information is necessary for us humans when the system grows, and the need is increasing exponentially with complexity.
With increased quantity and complexity, solely communication will not serve
But, with all types of big information exchange or in the case of complex information, that for example is needed when solving complex problems, solely communication will not serve without at the same time use documented information. The reason for this is, due to the high number of parameters we need to keep in our head at the same time. Complex problem-solving requires also documented information that is continuously updated, through numerous iterations, which are written and/or oral, until enough new knowledge has been acquired in order to solve or attack the problem. This is valid irrespectively if the problem can be attacked directly, or if it is a built-in problem within our way of working, in which case we first must ask why to find the root causes, which is also a complex problem to solve. The documented information for the solution will consist of writing, pictures, charts, diagrams, structure, simply what is needed to make the documented information as comprehensible as possible.
The scientific explanation to why we humans have difficulties to solve complex problems without documented information, depends on Miller’s number [8], that states that we humans can only keep 7+-2 things in our short-term memory. These things can be of different character, like numbers, words, terms, sounds, other impressions or thoughts in the short-term memory at the same time. This means that our short-term memory will not serve when the number of parameters steadily grow, which will be the case with an increasing complexity. The effect of Chinese Whisper is also the result of Miller’s number.
Documented information at agile way of working at scale, is a very good support
Conclusions that can be drawn from research [9] show also that the use of documented information at software development, support central elements as flexibility, productivity, knowledge spreading, maintenance, documentation quality and communication in companies that works with an agile way of working. The research shows validity for both small-scale agile and big-scale agile regarding these central elements, even though the greater effects are even more tangible in big-scale agile. Overall, this leads to the effect of greater customer benefits and internal benefits.
And all above goes hand in hand with science and also our common sense; the bigger system, the more complex to make, and the more complicated the final product will be, which makes it impossible to keep everything in our heads. And, when it is too complex or complicated, it is even not possible to have communication too long, until we concurrently need documented information as support.
This means that we already from start need to have better overview, structure and order for our system, not only in order to develop it, but also for continue add functionality to it and to do maintenance on it. If we also to this add high security and that it will have a long life-cycle, we need even higher requirements on the documented information, to be able to achieve the needed overview, structure and order. Also adding many teams working at the same time on the system, the requirements will further increase.
Miller’s number also explains why it is so common that we try to solve symptoms
This phenomenon becomes especially apparent, with all fruitless attempts to solve symptoms, even though it is a well-known fact and common sense, that it is impossible to solve symptoms. The reason is that it looks like we have found a solution, since we do not have the ability to keep enough parameters in our heads, to see that the solution will not fly. And this is especially valid, of course, when we use only communication, especially with excessive information, and no documented information. But, without finding the root causes, all our solution to the symptom will do, is sub-optimising on the wholeness. This in turn means innumerable unintended consequences, which we not have the ability to understand. This makes all communication without concurrent documented information in these cases, only to become an enormous risk-taking. If only oral communication is used, the result will only be un-objective, and directly faulty standpoints and solutions. And for solving complex (intractable etc.) problems, oral communication is definitely not enough, so beware when someone favour oral communication in these cases, since there stand point and arguments may instead be meagre and inconsistent, when written down. And if we think about it, master suppression techniques are always oral, never written, which is most probably not a coincidence. So, to avoid un-objectivity we need to get the discussion and solution down on paper, and if we do not, we will have high risk for polarization. Remember that this is not politics, where we can be subjective and have our opinion, since it is often very hard to prove if an argument is right or wrong. In this case we know that symptoms can never ever be solved, so to have another standpoint is not subjective, it is un-objective.
This is especially apparent when we try to scale up an agile way of working, by making a bottom-up transformation. The consequences of that are actually that we are trying to achieve the impossible, namely to solve symptoms in order to get a united and well-functioned wholeness. Why? The problem is that there is no systems design made of the organization from start, not even a hypothesis has been considered, on how the different part of our organization will work together to accomplish the purpose of the organization. Every way of working, no matter context or domain, this means a false integration of the parts, to become the wholeness of the organization. The reason to that it is only a false integration, depends on that an integration to a wholeness (and the appurtenant verification and validation on the wholeness), presupposes an already done systems design. A neglection of the systems design, will consequently give a high number of insolvable symptoms on the parts, with an exponential increase of symptoms over time, no matter how the wholeness has been intersected. The only possible solution to this false integration, is to dissolve the problems and their root causes, by doing the (at the start) neglected systems design.
Metadata
Metadata [10] is data that provides information about other data, but not any information about the content of the data, as for example a picture or the text in a message. Metadata can be visible as sometimes in blog posts or invisible as in HTML (if you do not know where to look for it of course ;-))
By using metadata, we can follow-up, interpret, search and sort, both easier and more efficient. Metadata will especially enhance searching, because it is easy and fast to search through large amounts of material. One of the most common applications is within documented information, where metadata is used in the document header, to give answers on such as the documents title, creator, last person that changed the document, status, type, version and date for version.
Version control
A new version [11] is an iteration of an existing artifact, documented information, software code, hardware module, and so on, simply something that has been updated and is different than before. Version control [12] is needed to be able to differ between variants of the same artifact, so faults can be corrected, change the artifact or expand it. Version control implies that earlier versions of not only documented information, but also source code files, configuration files and binary code, can be recreated, and changes done in earlier versions can be tracked. Version control is not only to get structure and order, it also opens up for parallel development, and where correction of earlier versions in parallel with advance of the existing version also are practicable. Another particular advantage is when many persons and teams work within the same system. Version control has existed as long as people has been able to write, most probably much longer, but got even more important since the birth of computers.
To achieve version control, changes are generally identified with a number- or/and letter code, which is called revision number, revision level or only revision when a release is made of a system, including revisions of all its part. Normally every version also is equipped with metadata in form of time stamp for the change, who made the changes, but normally other metadata is available.
The bigger a system becomes, the more documented information it will consist of, and the more employees and teams will work, in order to reach the solution of the system. This work will be done on different levels, with everything from requirement handling and system documentation down to the actual coding and release of the system. This will all together make the complexity to increase exponentially the bigger the system is, and one way to decrease this complexity is by version control of all the artifacts. The more teams that work with the system, will increase the complexity further. When the complexity for big systems is reduced, it is done top-down in different levels, where the system documentation is on the top level, and can be seen as a mere paper product, regardless if the realization is software or hardware.
Revision [13]
When a developer updates a part of the system, a version is typically a minor change, something that addresses issues in the original release but not enough changes to warrant a new major release. A revision can be seen as a controlled version. Webster’s dictionary describes a “revision” as the act of revising, which is to make a new, amended, improved, or up-to-date version. Back to the software analogy, a revision is seen as a major release of the software.
Architecture (product structure)
At all system development, a suitable structure like an architecture describing the components of the system, is good to have for small systems, and vital to have for big systems. An architecture is achieved through systems design, which reduces the system in smaller and smaller parts (components), level by level. We will not go into how the systems design is made, but the more complex, the more iterations and prototypes will be needed, see this blog post about Systemic Organizational Systems Designs – SOSD for more information. The architecture is appropriately represented by a hierarchical tree structure, that will grow top-down, according as the system development progresses.
This will make the architecture with all the components on different levels, an excellent basis to be able to achieve overview, structure and order, that is the need of RT. On every level of the architecture, including the top level, i.e., the actual system itself, we put all the documented information that has been used at the systems design of the component(s) and the results.
By this systematic approach, we can reduce the system into adequate granularity, before we start the realisation of our system. For the realisation of the system, we can use any way of working, traditional waterfall with I-competence teams, agile with T-competence teams, Lean product development with mixed I/T-competence teams, or others. A good architecture is a prerequisite to ultimately achieve a high quality on the system.
It is important to understand that every level of the architecture consists of documented information in form of artifacts, and that it is not only the readable source code, as leaves, at the bottom of the tree hierarchy, that are the only artifacts.
Baselines
The bigger system, the more complex it is to develop, which in turn require an architecture with more levels for us humans to be able to sort out the complexity. This of course also means that different competences are needed for respective level of the architecture, where higher levels are more paper products and lower levels are about the actual realization of the system. The reason for using baselines is briefly, for different teams to be able to work on different levels of the system at the same time. This means that when having a release to the customer/user, we are able to see the connection between the WHAT, meaning the functional and non-functional requirements, the system documentation with the HOW to realize the system that is received after the systems design, and the actual system realization. Baselines on different levels are of utter importance, no matter if we are developing a house, hardware, software, or others that is released.
Baselines also makes it possible, or at least much easier, to track the revisions of the different (released) artifacts, that was part of the release. Without baselines, the risk is that we when having incidents and found faults at compliance tests, cannot find the root cause to the problem, and therefore cannot achieve a robust solution. Also, the responsibility for different levels of the architecture becomes clearer with the use of baselines for each level.
To be able to handle baselines at all, we must have two things in place; an architecture with the appurtenant documented information per level, as well as version control for every single artifact, not necessarily by the same version control system per level.
Common baselines are; functional baseline with the requirement on the system, the allocated baseline with the system documentation achieved from systems design, the design baseline with the detailed design documentation, the product baseline with the actual realization including configuration files, and finally the release baseline that consists of all the artifacts on all levels and their respective revision. The mentioned baselines make it obvious about the risks we will have with a bottom-up transformation to agile at scale. Instead of the needed top-down systems design, the teams instead start with the actual realization of code from functional requirements put in the parts (buckets), and therefore neglecting the two first baseline levels. But, with the high complexity in a big system, where we except the need of traceability, also can add non-functional requirements like security, legal, fault handling, etc., the risk is exponential if we try to a posteriori put together the system. Without the allocated baseline we do not know why our system is not working, where the only solution to this problem is to make the missing systems design, which is the only solution to this root cause. That in turn need us to have the requirements on the system first, so we can make our functional baseline.
A baseline handling top-down is consequently a necessity at the development of big systems, and the different types of baselines mentioned above, is normally established at different tollgates in a way of working. This makes it possible for lower levels in the development chain to start to work with their parts, when the revisions of artifacts on a higher level have been baselined. This also makes it possible to withdraw new versions of the artifacts for continued work on the higher level. It can for example be the allocated level with the system documentation that need to be analysed, depending on that the functional baseline level above has updated the requirements. It can also be that early system tests shows that the systems design needs to have some updates.
To work with baselines, is to work in a systematic way, so that we at the end can achieve RT, which in turn is a necessity for high quality. It is therefore important that an elaborated and structured way of working according to the above example with different baseline levels, for the baselines to be useful. To have version control on all artifacts, but only take a snapshot of their revisions at the releases, cannot be taken for a release baseline. It will indeed show what revisions of the different artifacts that we had at the release, but it does not say anything from which system requirements, the different parts of the binary code can be derived. It is also a higher risk that changes in higher levels are done without control when we do not have a systematic approach with baselines on different levels.
Configuration Management
Configuration Management goes under the slogan; “It shall be easy to find the right thing and its origins”.
In a CM report from 2013 [14] the believe is, as a result of the entry of the agile way of working, that the market of CM tools would expand due to that. But what has happened, is that the market for version control for software have exploded, but where the market for CM tools for RT from ideas to code, unfortunately has imploded. The market for task management programs within software development has exploded as well, where JIRA and Rally are good examples. This is not so strange, since small scale and parts and the corollary aggregation, are counselled within agile, which results in that systems design starts to be neglected, especially when using agile scaling frameworks. The problem is that for big systems we need the systems design, the overview, the structure and order the most. And with this reduction or MECE thinking that all big systems can be reduced to parts, it seems like the version control of only software and task managements programs that only divide the functionality into parts/tasks, would be enough. This thinking in turn of course makes it impossible to understand that the need of good CM tools is the same, if not bigger than before as a result of the flexibility that is advised in agile software development. The CM report also clearly points out that the CM tools must be more flexible in order to meet the need of the agile way of working, and that this increased flexibility also demands higher requirement on the RT. And with this lack of proper CM tools for software development, the fact is that we neither have the required RT, built into the tools.
This means that it is an imminent risk that the tools over time will lose more and more of this RT that is always needed for big systems, since the tools tend to follow the artifacts that now can be found in for example agile scaling frameworks. And many people will think that the tools follow the good way of working, supporting the right artifacts needed for system development of big systems. The risk is then high that everything with wholeness disappears, as the need of early non-functional requirements, since they are building the systems design and architecture, system tests, traceability, fault handling, security, etc. What has already happened is that more and more discussions are about CMS (Content Management Systems) like WordPress, handling a system of artifacts, compared to a CM tool that handles RT.
It should also be added that the top management approach to quality, is very important regarding to secure that the CM function is viewed as necessary and prioritized. An apprehension is, as a result of an agile way of working at scale, that the agile teams make themselves to autonomous in comparison to the wholeness. In their isolation they take care of their own CM activities, which makes them uncomprehending to the need of the CM function. This will lead to that even that there is an apparent need of RT for big systems, the risk is that the CM function is removed, before it is understood that we have not handled the wholeness correct. This is not only valid for the CM function, but many of the functions that took care of the wholeness, when a bottom-up transformation is made to agile at scale, due to that it is easy to realise the need too late.
We instead need to have our eyes open, have contact with our common sense and use our critical thinking, when we consider our needs, which normally the teams, and the people close to the teams sees. If we have preconceptions the risk is high that we lose the wholeness, and starts to remove CM functions or test coordinators, since we do not have that in small scale Agile.
It is also important to note that CM is not only a function that we add to our organization, but rather a part of a systematic and structured way of working within all parts of the organization, which is necessary for all functions that indirect works with quality.
Tags and labels
A tag (or label) is a type of metadata, and is useful to enhance searching functionality. At snapshots of a system only taken at new releases, a tag can be seen as synonymous with a release baseline snapshot, if all artifacts have the same tag, for example the release number.
As a result of the early digitalization, discussions about tags as complementary to traceability was discussed already in the 1990s. With the agile way of working, tags have got an opportunity for renaissance, due to the general absence of overview, structure and order. Tags will then increase the search functionality and thereby also the traceability, which without the need of RT, can be enough when only a few agile teams develop a software system that is small, has low security and with a short life cycle. With this kind of small software system, it can make refactoring possible not only on the parts, but also on the whole system, since the complexity is lower.
Note! This means that when the system increases, refactoring is not a very good solution to taking care of an improper (or no) systems design to achieve the architecture. A crappy systemization always leads to bad quality in the end, since quality can never be tested into the product, no matter all automated tests in the world. The quality needs to be built into the product from start, as Deming states, and that goes for the wholeness, and not only the parts. And to try to rebuild the architecture to fulfil non-functional requirements a posteriori (in hindsight), is really the wrong road to achieve good quality. The same goes with trying to solve a crappy systemization by trying to repair the parts, since that is clear sub-optimization. Bottom-up scaling easily leads to crappy systemizations, when the focus is only to deliver functionality and value to the customer fast, and no focus is to build the product right, leaving the systemization to its own destiny.
But, since the intention with baselines is a systematic and structured way of working, to achieve RT top-down (and back), so are tags not synonymous with baseline handling. That is why tags only shall be seen as a complement to baselines, to enhance the searchability, in the same way as metadata.
The conclusion is that for big software systems, tags are only a complement to baseline handling, and not a substitute. For small software systems, with no security and short life-cycle, tags may be a substitute, but at risk.
Requirements Traceability (in depth)
Now we have dissected all the areas that RT is grounded on, which means that we now can go into even more depth of the world of Requirement Traceability.
Within systems and software development the term RT is used for the ability that during the development be able to follow the requirements both backwards to the need from the stakeholders as well as forward to artifacts like design documentation, source code, test cases and error reports. The term Requirement Traceability – RT, will be used consistently in the blog post. This because the term traceability is used in considerably easier contexts, like supply chains. This has hollowed out the originally definition to only mean to be able to trace within a system of connected artifacts, which is not adequate for the Complex domain in the Cynefin™ Framework, where system development belongs. RT is all about to have overview, structure and order in the system development, and it needs to be done top-down, which can be understood from the name, since all system development starts with the requirements, both functional and non-functional. RT has nothing to do with how often the system is released, every quarter, more seldom, or more often.
The following definition is common [15][16]: “Requirement Traceability is aiming for the ability to follow a requirement, both forwards and backwards during the development, i.e., from its origin, through the specification and development, to the following release in production and usage, as well as through maintenance and iteration in all of these phases.” **
It is important to understand the origin of the requirement, if it is from the enterprise, market responsible or from the user, to be able to see the value of the requirement, for example the user, in order to prioritize the requirement. It is also important to add that new requirements cannot be added at lower levels, firstly for the RT itself of course, but secondly also because new requirements can lead to that the systems design need to be looked over. This is especially important in big systems, which means that no team or team of teams can plead autonomy, since new requirements always need to be analysed first, to understand possible effect on the systems design. To be able to see the requirement in comparison to all artifacts is associated to, for example; models, analysis results, design, source code, test cases, test procedure and test results, is also important.
Requirements on RT can also come from standards, for example ISO/IEC 9000 and is required for different certificates, often within safety* critical development. Within safety critical development the RT is especially relevant, and some general safety standards are DO178C, ISO 26262, and IEC61508. Within IT security*, the term traceability is one of the elements that is elucidated in order to judge an IT systems security level. It is common that safety critical requirements need to be verified and this verification can be demonstrated through RT. One way to enhance the RT is to maintain requirement traceability between requirements and test cases, with a requirements traceability matrix for the whole system, as well as for the parts of the system. This is once again especially important for bigger systems, where it is a big challenge to keep track of all the requirements, but where the challenge does not give a reason for not having RT at all.
The requirements on the system have different sources, like; enterprise, users, UX, etc., that after analysis of the requirements, generates function, non-functional and technical requirements. To perform this analysis, to distil WHAT the system shall do, is a process that shall be iterative. To achieve good RT for a system and its parts, RT all the way from the original requirements down to the generated binary code and back. Especially the non-functional requirements need to be available early in the development of the system, since they are a very important input to the systems design, i.e., HOW the system will work on the highest level. The systems design is not only generating the architecture and the system documentation, that consist of all parts respective functional and non-functional requirements, but also is the start for the work with the system tests; system integration, system verification and system validation. Both the functional and the non-functional requirements on the whole system shall be tested and evaluated before put in production. When producing the detailed specifications to be able to do the design of the parts, the traceability to the system documentation is important, but unfortunately often is missing, but that is a must to be able to achieve RT.
RT is also important to be able to understand where in the system documentation (incl. the architecture) and the system realization (the code) that respective top requirement can point at. This is also valid to be able to decide if it is a bug, or if the system documentation is erroneous, or even that the requirements are erroneous, or should be challenged because they are unnecessary tough. Even documentation around test is important that it is part of the RT, so we can understand what tests that have been done when a bug is found in the code. This makes it possible to understand what has been tested when a bug is found in the code. And with this understanding, conclusions can be drawn if tests have been missed, not done for a reason, or even are missing, which can lead to changes of the test cases, or changes in the test procedures to increase the test coverage.
Important to add is that thorough studies from 2015 shows that code changes with and without requirement traceability demonstrated big benefits when requirements traceability was used. Developers completed tasks with support of requirements traceability 24% faster and 50% more correct [16]. Other performed studies show the same significance [16]. With implemented requirements traceability an organization has the possibility to traceability, that is not only in the heads of the people. This leads to the RT between different artifacts, especially the written ones, are achievable as documented information also after people have quit. We should also consider that the bigger and the more systems an organization have and how big the organization is, the more the complexity will increase. This leads to that it is impossible as well, to keep the RT in peoples’ heads, which is a risk inherently, since when the limit is passed, the organization will stand with no RT at all.
To be able to reach good RT, a good overview, structure and order is needed already from start. This is normally an architecture as a result of a systems design, where the system is divided into parts, that on CM language is named as configuration objects. This means that to be able to keep a good RT, the tree of configuration objects will increase the longer the development proceeds, to finally result in readable code and configuration files for the whole system. By doing this, we will achieve RT early in our development, which is important so we not only get low level source code artifacts with a release number in form of metadata, without connection to the original requirements. When we have a software fault, we need to be able to track the requirement on that piece of software code in the tree structure above the code. This is not only valid for the system documentation, original thoughts regarding the system etc., but also in order to reach the system test cases, system test results, etc., so we can find the root cause to our fault. This tree structure used for achieving RT, is not at all coupled to a traditional way of working, which appears to be a common misunderstanding. The tree structure is not only a necessity for achieving RT in big systems, but also for us humans to have overview, structure and order in the big system, which also is an enormous support for the software teams daily work, as the studies showed.
Worth to mention is also the term modular structure [17] that sometimes is used erroneously in connection with agile way of working, and that a modular structure can be used instead of a tree structure. A modular structure is a system of modules, with well-know and explicit interfaces between the modules. Here the systems design has not only considered the existing modules and their variants in consideration, but also suture variants built with coming technologies. Platforms with component modularity within the car industry is one example of a modular design. A modular design therefore requires even higher requirements on overview, structure and order, since it also will be variants on the different systems that is possible to generate from the platform. We could say that a platform gives a number of different variants of tree structures, one for each released system. A modular structure is therefore not a structure that we can add new artifacts to anyway, in the form of documented information or readable source code. Regardless way of working, it is all about that there are tree structures to achieve RT, overview, structure and order at all in big systems.
Today for software development, the support for RT is poor, i.e., requirements traceability from idea to releasable code. But that is not strange, since the agile way of working has its origin from small, non-complicated systems where the focus is on the right product, and not on the product right, and without overview, structure and order, there is not even possible for having RT at all. That one of the Agile Manifesto starting-points, is to value ready code higher than documented information also add to this matter. The Agile Manifesto is consistently focusing more on the teams that work and the functions (WHAT) the customer need. And very little focus is put on the system and its solution, i.e., HOW the system shall be developed to become a unified and well-functioning wholeness. A significant observation is also that for big systems, especially within bank, insurance and governments, develop digital service to the customers and from the beginning then already know WHAT the product is, i.e., the right product is already known. This means that the development of HOW the system shall work (the product right) never, strictly speaking, competes with WHAT the system shall do (the right product). This in turn gives room for, in combination with a good road map and proactive planning of how the system can be developed, iteratively and incrementally work with the HOW solution on the system level, before the teams start to work with WHAT the system shall do.
This was all for this blog post.
C u soon again.
*Safety and security are unfortunately often used synonymously, but there is a big difference between them two. Safety means free from harm or danger that is unintended, while security means freedom from harm or danger that is intended. For example, a passenger aeroplane needs to have high safety, while an IT system needs to have high security.
**This definition especially highlights the requirements, which indicates the tight coupling that was established between traceability research and requirements handling research in the 1990s.
References:
[1] The refactoring [2] is used to enhance the design, structure or/and the implementation of the software, i.e., the fulfilment of the non-functional requirements, without changing the functionality. Ten years before the Agile Manifesto was released in 2001, the term refactoring was coined, even though the actual practice had been carried out already for decades. Refactoring is derived from the English term factor, which is the same thing as decomposition, i.e., to reduce the complexity by making smaller components (parts) [3].
[2] Wikipedia. Code refactoring. Link copied 2021-10-20.
Code refactoring – Wikipedia
[3] Wikipedia. Decomposition. Link copied 2021-10-20.
Decomposition (computer science) – Wikipedia
[4] Wikipedia. Information. Information. Links copied 2021-12-05.
Information – Wikipedia
Information – Wikipedia
[5] Wikipedia. Documentation. Link copied 2021-12-05.
Documentation – Wikipedia
[6] Wikipedia. Kommunikation. Communication. Links copied 2021-10-26 and 2021-12-05.
Kommunikation – Wikipedia
Communication – Wikipedia
[7] The definition of documented information is documented in ISO 9000:2015, and a short description is as follows: ”Documented information can be used to communicate a message, to be an evidence that what has been planned also have been accomplished, knowledge spreading, or for spreading and preservation the experiences of the organization.”
Link copied 2021-10-25.
Vägledning för krav på dokumenterad information enligt ISO 9001:2015 – Svenska institutet för standarder, SIS
[8] Wikipedia. The magical number seven, plus or minus two. Link copied 2021-12-05.
The Magical Number Seven, Plus or Minus Two – Wikipedia
[9] Dokumentation inom agila mjukvaruutvecklingsprojekt. Kandidatuppsats från Lunds universitet av Nathalie Monroy, Emma Pehrsson, Elin Strid. Augusti 2015.
Link copied 2021-10-25.
LUP Student Papers – Dokumentation inom agila mjukvaruutvecklingsprojekt
[10] Wikipedia. Metadata. Links copied 2021-10-28 and 2021-12-05.
Metadata – Wikipedia
Metadata – Wikipedia
[11] Merriam-Webster. Version. Link copied 2021-12-03.
Version – “a form or variant of a type or original”
Version Definition & Meaning – Merriam-Webster
[12] Wikipedia. Versionshantering. Version control. Links copied 2021-10-25 and 2021-12-05.
Versionshantering – Wikipedia
Version control – Wikipedia
[13] Merriam-Webster. Revision. Link copied 2021-12-03.
Revision – ” a result of revising : ALTERATION”
Revision Definition & Meaning – Merriam-Webster
[14] Configuration Management i teknikinformationens tjänst – en antologi.
(Configuration Management in the service of technology information – an antalogy)
Link copied 2021-12-05.
https://www.google.se/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwj52Lboh6fzAhXKlYsKHe6mBxYQFnoECAYQAQ&url=http%3A%2F%2Fmiun.diva-portal.org%2Fsmash%2Fget%2Fdiva2%3A675984%2FFULLTEXT01.pdf&usg=AOvVaw2jOSKOHtTchlxByZ0ywX0V
[15] Wikipedia. Spårbarhet. Link copied 2021-10-25.
Spårbarhet – Wikipedia
[16] Wikipedia. Requirements traceability. Link copied 2021-10-25.
Requirements traceability – Wikipedia
[17] Wikipedia. Modular design. Link copied 2021-10-28.
Modular design – Wikipedia