

As stated earlier, the ability of systems design (and systems test) to reduce transdisciplinary complexity/ complicatedness when making new products or platforms, is one of the most important ones in product development. If this is not done correctly, it is easy to end up with just a system sketch (more like a jigsaw puzzle) and not a system architecture, see this blog post for a deep-dive how to be sure to not get it wrong. See also this article, where the difference between complexity (product right) and uncertainty (right product) are defined, which is important when reading this article.
A resulting system architecture is also a necessity for us so we can get an overview and understanding what we are doing and how our system actually looks like, which is also an important complexity to reduce, especially regarding development of bigger products. The system architecture therefore gives us the needed structure and overview, as well as how the parts fits and interact with each other, from our first thinking to a ready product. A very big product (system) can also need sub-system architectures, which means systems design per sub-system as well.
Here is an attempt to explain why reducing transdisciplinary complexity/ complicatedness is so important in order to achieve a proper system architecture:
The specified requirements on the respective parts, to be able to fulfil their respective functionality, as well as their respective non-functionality, i.e., the parts’ interactions to become a unified and well-functioning whole, all in order to fulfil the specified functional and non-functional requirements on the whole, can never be set in advance when we have transdisciplinary complexity/ complicatedness. This is what is meant with transdisciplinary (integrative) complexity/ complicatedness; we cannot specify the solution of the respective parts from start. Instead, we need to integrate the parts (from a well-though-out systemic hypothesis) to a whole, and verify and validate the whole, in order to see if our assumption or hypothesis, the systems design on the whole with all its parts, was correct. And regarding this reduction of transdisciplinary complexity/ complicatedness, there is no difference between hardware and software. Reducing transdisciplinary complexity/ complicatedness often means prototypes in order to gain new knowledge from the tests on the integrated whole, until we have all the knowledge needed for developing our product. This is very different from disciplinary complexity, often called research, which is about digging down into a discipline in order find new science or/and new technology, and therefore mostly is a part of the way of working for hardware. But, as this also is about reducing complexity, reducing disciplinary or transdisciplinary complexity has one thing in common; we do not even know if we will find what we are looking for, and if we find it, we will not know when.
So, we can never fully specify the requirements for the subsystems (parts) when having high transdisciplinary complexity, since it is impossible to have that knowledge in advance, which is what Alicia Juarrero [1] explains as “trying to reach new cohesiveness”. This is why all new product development, no matter domain, is highly transdisciplinary complex. Simply, we can only achieve new knowledge at the synthesis (integration) of the parts to a whole, which also includes the systems tests of the whole, since we can never specify us out of any complexity. From this we can also deduce that a part in itself can never be validated, until the whole is both verified and validated.
If we have not done a systems design on the total system (the WHAT), we cannot claim that we have taken care of the non-functional requirements especially, since lower levels then do not know the non-functional requirements on their respective parts. Systems design is about making HOW the parts fit together, interact together, to become not only a united, but also a unified and well-functioning whole, which means the what the respective part is responsible for according to their respective functional and non-functional requirements. Just to divide the functional requirements of the WHAT into smaller functional requirements of what per respective parts, will not do the job of systems design, see this picture, Systems design is always top-down. Just dividing functional requirements into smaller parts, can be seen as implementing gigs, where a more thorough deep-dive can be found here.

It is also important to point out that the outcome from the systems design is not only specific functional and non-functional requirements that will be put in the requirements specification for the respective subsystems. There will always be general specifications that all of the subsystems need to follow, where especially interface specifications, like communication protocols, including solutions to be implemented for cyber security; functions like authentication and authorization. These general specifications are also important for achieving a proper traceability, as well as that they also represent the intentions of the systems design for communication between the subsystems, that all subsystems need to follow, otherwise the solution on the whole will not work. If the subsystems themselves are the owner of these general requirements, by putting them in their local subsystem specifications, changes in the systems design regarding the communication, for example by adding extra cyber security functionality, will not be reflected in the subsystems automatically. It is then also a high risk that these general requirements are modified or deleted locally in the subsystem specifications, by mistake, or due to that the intention has been lost.
It is also worth mentioning that general specifications for communication, also need to consist of the high-level requirements as well as the description of the total communication solution. The reason is that when implementing the SW communication module, it will be on the lowest level of abstraction for testing, since it is a module, meaning it is not reasonable or in many times not meaningful to verify the low-level requirements, instead the higher-level requirements will be tested against the solution. A communication module must also be tested thoroughly locally, since the test of the whole subsystem that is performed later, will test the whole subsystem’s functionality, including communication and all the other functionality at the same time. This makes any communication module somewhat different with a clear function that can be seen from the outside, in comparison to all other modules within the subsystem, that together achieving the other functionality of the subsystem, i.e., the black box. A control algorithm, to maintain vehicle speed, is an apt example. It consists of many different subsystems, that together implements the solution, but where no subsystem can be understood from the outside, since they together achieve the function “maintain vehicle speed”. See the following picture, communication protocol testing including cybersecurity.

We will now show two different scenarios of what will happen when we are not taking care of non-functional requirements. Note that no one of the two scenarios, and their examples, will of course work at the integration of the parts and verification of the whole, due to neglecting the need of a well-thought-out systemic hypothesis.
In the first scenario, common from agile at scale, which just divides down the functions on the whole into the parts, without taking care of non-functional requirements like maximum 100 milliseconds respond time on the whole systems. By neglecting this non-functional requirement, this will end up in functions that will look like an easy and fast implementation within each of the parts, since the respond time has not needed to be considered per the respective part, actually totally neglected, since there is no systems design done. This will of course give tremendous performance problems, since all the parts are under-worked, which will not be visible until system tests of the whole system have been done. Unfortunately, systems test for the whole, is also another common neglection in agile at scale, which means that we will not even understand that we have an inferior system until very late, most probably too late.























Therefore, the plan for the whole initiative must always consist of deliveries of the parts to Integration Events – IEs, where we integrate the parts and verify the whole, in order to get knowledge of our systems design, our hypothesis, i.e., for each layer. In the beginning, when the transdisciplinary complexity is high, we just need to put mocked parts together, to get knowledge about if they are united and unified as expected. Later on, these IEs will continue, but instead every team is then delivering their important piece, to be integrated, verified and validated to the whole on the wholeness level for big initiatives. Note that the term CI – Continuous Integration, is not synonymous with one or many IEs, not even the last IE before release. CI is about adding new tested code to the existing code, to avoid Big Bang Integration (and of course also a big bang for the verification and validation) at the end, but does not automatically include that the total code is verified and validated. This induce that huge problems still can be the case, especially for doing the big system right, see this blog post for a deep-dive. The systems design and systems test can therefore be seen as necessary iterative experimentations, but from well-reasoned hypotheses continuously updated. By that approach, we are able to gain new knowledge, so we can reduce the transdisciplinary complexity (unpredictable) to transdisciplinary complicatedness (predictable), before starting an initiative.
Making a new future-proof modular platform has even more transdisciplinary complexity, compared to making a new product or system, due to the fact that more parameters need to be taken into consideration, for the platform to be usable, maybe more than a decade ahead. This is also valid, when we for example are combining different existing monoliths (some kind of disciplines), to a common future-proof modular platform instead, since we only have the disciplinary science and technology for each monolith. This makes the new platform a novel product (system), since the new combination, i.e., putting all the non-functional requirements for each monolith together, means that the new solution is novel. Put another way it means that, we can never aggregate the respective solutions of the monoliths to a whole, even though we can aggregate their respective non-functional requirements to the full non-functional requirements for the whole.
Changes on an existing product or variant of it, instead need only exploitation which means reducing transdisciplinary complicatedness. This means that the results from a few prototypes analysed by experts, will give us the needed knowledge so we can do the necessary final updates, integrate, verify and validate to a unified and well-functioning whole. This is why an iterative approach with prototypes as a solution to this, are self-evident in hardware product development, an integral part for us humans, since probably hundreds of thousands of years, in “hard” domains when reducing transdisciplinary complicatedness. These iterations can be seen as exploitations, but from well-reasoned hypotheses of course, to be able to gain the last needed new knowledge, and by that approach, reducing transdisciplinary complicatedness, still iteratively, until the product is finalized. Note here that when having monoliths, we cannot add any requirements for the last prototype, since the last prototype always is in the clear context, meaning that the solution is checked a last time, not that requirements are added, since then we are not sure our prototype will work. For monoliths there may neither be possible to add future functions or user functions, and especially not non-functional requirements, since they in most cases will change the total system architecture. When having future-proof modular platforms instead, we can of course not add new non-functional requirements that will affect the system architecture (if that is not already considered that it won’t). But the reason why making a future-proof modular platform, is because we in the future will be able to add especially new functions and user functions to our platform, without breaking our system architecture. This is especially valid for the automotive industry, many time with a way of working with roots in the Lean Product Development system. Future-proof modular platforms is an effective strategy in order to handle the uncertainty context, both regarding the backend (changing the technology for subsystems), as well as for the frontend/UX (new user functionality), where the latter means that we do not need to know exactly what functions or user functions tom implement, or the order of them, we just need to have “room” for them, i.e., in the hardware, or volume, weight, heat dissipation possibilities, etc. for hew hardware modules.
It is also necessary to consider that the way of working is following this top-down and transdisciplinary approach, considering all needed disciplines and competences in order to do a proper systems design. This top-down approach is very important, so we do not skip (ignore) any steps from start, or trying to start on a level in the middle of our product, without the right requirements figured out on the parts on that level. Here below we will show some typical scenarios that are common, but that we must avoid, in order to not risk our product development. The first picture, systems design to achieve the architecture, shows the intended total way of working, and is just a variant on earlier pictures:

Our total way of working of course need to support this top-down approach needed for achieving our system, our product, with all the different how, i.e., top-down and level per level. This to avoid generating symptoms, that when having them, often occur very late in the PD process, especially when early testing of the full system also has been ignored. Since product development is transdisciplinary work level for level as shown above, and domain independent as well, here is another picture, with a little other approach, showing also the transdisciplinary work needed by all the disciplines within the organization, Transdisciplinary Way of Working needed – showing the disciplines:
![]()
As we can see in all transdisciplinary work, all the disciplines within the whole organization are dependent on each other, in order to be able to know what to do on the next level, regardless if there is about planning or reducing complexity. And since a lower level depends on the output from the higher level right above, that means that we always need to start from the top, i.e., which gives the top-down approach. The reason why the systems design is a fluffy cloud, is because in order to make a new or especially novel product, we always need to gain new knowledge, which means reduce the complexity. This is why the method TDSD has been developed, including its system skeleton thinking, per level. This gaining of new knowledge, means iterations of a level, as well as go back from a lower level to a higher, since the systems design on the higher level, needs refinement. Remember also that sub-optimization will always occur when trying to focus and optimize the parts themselves, i.e., ignoring the needed transdisciplinary work in any product development way of working. From that we can also deduce that changing the parts from disciplines to dimensions, i.e., any other way to get parts (overlapping or not) of the whole, without any top-down transdisciplinary work, will still only sub-optimise the whole.
It is also important to point out, that when we do not have any way of working, the requirements (What) for any level, also means that we need to make our way of working at the same time. This means thinking about the total PD process and its sub-processes, which can be different per level, until we reach the teams’ level. This gives that the What is not only requirements valid for the product, but also requirements required for the total PD process and its sub-processes. We therefore, as shown, at the same time need to think about how we will work with traceability, release management, planning, quality, documentation handling, tools etc., and level per level as well. Making pilots is one way to test the PD process, but given the above, means that it is important that the total PD process is nailed out top-down, at least as an overview, all in order to avoid sub-optimization. But unfortunately, many times it only becomes more of dry swimming of many sub-processes which are not properly connected, which then will only become a lot of different sub-optimizing activities, that only will lead to even more and more severe symptoms.
But we should also be firm, that we have the needed science about the organizational principles as a solid foundation, and where this series, with all its deductions, for example shows the needed top-down approach, as well as that the solution space for a PD process is dramatically decreased. This gives that it is secure, to make a total PD process implementation based on science. It is also preferred, compared to doing pilots that fully neglect science, and therefore only will lead to sub-optimization and a mal-functioning PD process.
What about when we from our needed top-down design already have a unified, united and well-functioning system, represented by an awesome systems-designed architecture. Will not agile frameworks for scaling then work when adding only pure software functionality?
No, is the short answer, since agile at scale never take care of the whole per se, since in an agile approach the functional requirements (epics, features, user stories, etc.) only are cut to smaller and smaller pieces at the same time as the non-functional requirements are neglected, i.e., there is never a proper systems design done for the total sum of the requirements on the system from start. Small-scale agile can via refactoring of architecture and code get some decent level of quality for short-lived products and with non-critical code with their incremental deliveries, often also using an E2E approach by picking user functions from a backlog (which in turn leads to an emergent architecture), is always risky business, even for small-scale software development.
The long answer proving this with simple reasoning and an example, clearly states the necessity of always doing a top-down systems design, not only for new systems, but also for existing ones, is as follows.
We always need to be aware of that software (and the data it needs) resides on hardware. This means that even if we have the perfect way of working for software, that enables us to make the perfect premium software, we are still at high risk for failure, if the hardware limitations in our total existing systems architecture are not considered. Because, the embedded hardware itself can be too slow for the new software, out-of-internal memory, external memory, communication capacity with other hardware, etc. This leads not only to that the embedded hardware will not fit in the existing architecture regarding non-functional requirements like volume, weight, heat, EMC, maybe the communication structure needs between the embedded systems need to be updated due to more data needed or faster transmission, which gives huge problems for the next integration level, and so on. This therefore means that for every software requirement we add to any existing and well-functioning sub(-sub)-system, we need to re-evaluate its existing systems design and system architecture for the total system before we start the implementation of the software requirement. This to be able to secure, where test-driven iterations will be handy, that the systems architecture can cope with the added software requirements, and not only when adding new hardware requirements, where a re-evaluation of the existing systems architecture is clearly understandable.
Apart from that software always resides on hardware, we always need to be able to make early integrations of different parts of our system, where of course the hardware and software integration to achieve a complete sub-(sub)system, like an embedded system, is of the same importance as the ability of early integrating HW(+SW) subsystems to the complete system. Here we also can have alternately prototyping, where a hardware prototype becomes available for software tests at an integration event, and at a later integration event vice versa. Isolated work where hardware and software are not synchronized, often leads to software ready first, and put on the shelf, and then when hardware is developed at a later time, changes is needed on the total specification of the subsystem, making a lot of the software to be just pure waste.
As you understand with the reasoning above, these problems will also be found extremely late with a considerable effort needed for finding the solution, since the root cause to all these problems was done way back in time and effects the system architecture of the whole system. This leads to late deliveries to the customer of our products, that will be more expensive and have bad quality. In best case it is only our margins that are affected, in the middle we have the risk that our Business Case is not sustainable anymore, and in worst case, we cannot get our product to work, even with discarded non-core functionality.
We therefore need to be vigilant to all kinds of decentralised way of workings for software, like User Functions and all kind of pure agile, or agile at scale approaches, when just adding more software functionality to an existing well-functioning embedded subsystem that is part of a well-functioning system. Instead, we always need to re-evaluate our total systems design and system architecture top-down, even if we add a single software requirement in one of our subsystems at the level below or at lower levels. Software and all the data it need, will always reside on hardware, and hardware always have limitations, it is as simple as that.
This means that a decentralised thinking regarding software is always treacherous even for systems that are not considered as embedded systems, if the hardware aspects for the added software requirements are not considered from top of the system. Apart from the tremendous problems that will arise, our awareness of them will be extremely slow, sometimes as much as years, until we realize that we need to update or adding new hardware. We shall though not forget that the software itself, especially at scale or/and when critical, always needs a proper systems architecture, which disqualifies decentralised approaches from start, which is shown with the System Collaboration Deductions. But, if you accept malfunctional software and have limitless hardware, then any software development approach is of course possible. But, when having critical products, and the ability to make a proper systems design (by systems engineering, not agile), then there is of course possible to use also an agile approach for the frontend with clear APIs to the critical backend. This last example is also why banks, insurance companies and governmental institutions to some extent has succeeded in implementing an agile at scale approach, since they are not touching the backend, and only concentrating on implementing new apps for frontend. Since apps (on close to limitless hardware in mobiles, computers, etc,) have been made towards existing backend to a great extent for many domains the last decades, it is the reason for the growing popularity of agile approaches. But, without knowledge about these limitations, the reason for failing in other contexts, especially when scaling up, in combination with areas where the hardware is not limitless, like embedded systems, i.e., separation of the hardware and software development is not possible, which directly implies that an emergent software architecture approach will definitely fail since the non-functional requirements’ effect on the hardware architecture is not considered from start of the development. To understand the hardware capacities like speed, internal and external memory, communication possibilities via different interfaces, etc., taking requirement after requirement from a gigantic backlog, will not be enough, i.e. we do not know if it 10 million or 10 billion lines of code, if it has time criticality, etc. With an incremental approach where software development not considers that software resides on hardware, it can take years, at the integration of hardware and software, until limitations in the hardware are understood.
Here is an example from the automotive industry, and what will happen with a decentralized thinking, when cybersecurity is added, to their ECU systems and CAN bus technology for hardware, a hardware concept that has been used for decades. If we regard cybersecurity as only requirements on software or most of them, the hardware side, which do not have the knowledge about the solution of software requirements, especially not for a new-comer like cybersecurity, will then not be in the loop for understanding the software needs on the hardware, when we are using a decentralized way of working. Neither will software with no or low knowledge of cybersecurity from start, understand if all the requirements are possible to implement in pure software on the existing hardware, or not. This is no matter if we use a User Function strategy common in the automotive industry that divides the User Function in a hardware and a software part, without a systems design, or an agile at scale way of working where software is separated from start omitting hardware limitations, that many companies in this industry has failed to transform to, or are right now failing. What will happen is that when the needed re-evaluation of the systems design is not considered, the software requirements will be routed to the software way of working and the hardware requirements to the hardware way of working. This will go on, for example level by level, until the software and hardware after their respective implementation, finally is integrated into bigger subsystems, or in worst case as late as the integration to the complete system, where we suddenly will find out the hardware limitations. This can take years, in comparison to first make a re-evaluation of the existing systems design and systems architecture, level by level, to understand what updated or even new hardware that is needed, in order to be able to implement the cybersecurity requirements. Finding things unnecessarily late is a reactiveness that is always a sign of a non-existing systems design from start, see this blog post for a deep-dive about reactiveness.
The necessity of considering the wholeness goes for any system; “pure” software on centralized hardware, or systems with software and hardware, but where it is especially clear with systems that consists of embedded systems, which means that without considering the total system architecture for the system from start, this can lead to the need of new hardware for the embedded system. This in turn, apart from delays, higher product and production costs, etc., can lead to overheating problems, EMC problems, or volume problems within the system, so that the cover for the product cannot be put in place. This in turn directly means that emergent architecture, a common term for agile at scale approaches, with this easily understood example, clearly is the wrong track in the case of embedded systems where hardware sets the clear physical limitations (of different kind). But, do not get it wrong about emergent architecture. It is wrong per se, especially for bigger systems, which System Collaboration Deductions theoretically clearly shows by using deductions from existing science about humans and activities.
It is also important to repeat how important to continuously integrate the different part of the system, as well as the wholeness of the system, what is called IEs above. This leads to that the development of the different subsystems, no matter if they are pure SW, pure HW or a combination, need to be synchronized so these IEs can be achieved. To just implement all the SW first, without hardware, is fully missing the point. The implementation of the subsystems needs to go hand in hand in order to at the IEs learn from each other’s early prototypes, as well as learn on the wholeness.
By decentralized thinking, the complexity in our system is not going to be eliminated, which is the reason for failure as shown above. But decentralized thinking neither make long-term plans, which is part and parcel of the approach, as well as that any team or team constellation (up to a value stream), only take responsibility for their own delivery, which neglects verification and validation systems and their environment, on the whole system. This also means that the need of knowing and keep track of all requirements, especially the non-functional requirements on the whole, are neglected as well. In decentralized thinking, as the name implies, no one is even able, to take care about the whole, which above example explicitly shows. Implicitly it also states that coordination, synchronization, orchestration, etc., i.e. anything in hindsight that still is omitting the systems design, never can do the job. This also means that companies that tries transforming to agile at scale, from a framework, does not fail because they in their domain implemented the wrong parts from a framework, but instead fail because the whole decentralized approach is a failure in any context that is harder than a simple context like production. The needed way of working for bigger products built on modular platforms, that have a life-cycle of decades, shall not be compared to the way of working that can go along for apps and consumer products, that not only have a life span of a few years, but that also are not considered as having the same criticality in their functionality. When having these kinds of modular platforms, it is a necessity to keep track of the understanding and maintenance of the system architecture for the modular platform, to be able to have it valid for decades, where for sure smaller updates will be continuously necessary to do. As soon as we have built our first release on the modular platform, not only the released product with its subsystems will enter the maintenance phase but also the system architecture of the modular platform.
Here are some examples when having non-complex tasks to solve, but where we still need to be cautious about the wholeness, since the solution of the seemingly non-complex task in a subsystem, never in advance can guarantee that the total system architecture will not be affected.
- The first example is for non-complex additional functionality or maintenance work (bug fixing). This is valid since in this case, we do not need to consider any extra non-functional requirements and we already have systems test for the whole as well. Non-complex tasks can of course (almost) any way of working successfully solve, which will look like this, non-complex tasks in product development:

A huge problem here, which is also the most common approach, is when you introduce agile at scale by showing how it works when only solving non-complex tasks, like maintenance. But, since that is not the reason why you introduce agile at scale in the first place, it really does not show any suitability at all regarding solving complex tasks, especially not like developing a novel product or a platform, i.e., since the whole life-cycle for a product always need to be considered for any way of working.
- Another example is also on a low level in the architecture, where the system architecture allows adding, not only local functional requirements, but also local non-functional requirements, like space for new subsystems. A CAN bus system for communication, where you can add new hardware units, with software functionality, is an apt example. It will then look like this, Adding modules to an existing architecture:
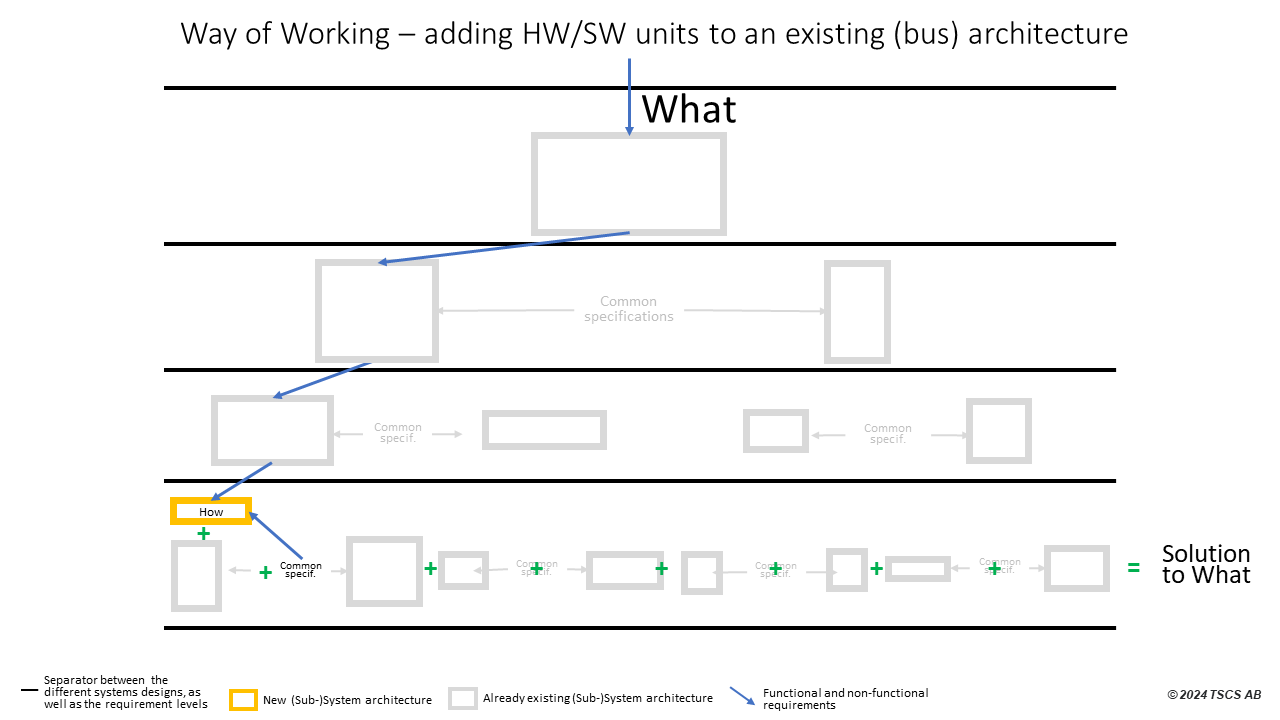
A problem with this last example is of course when it for one or more non-functional requirement (space, weight, memory, speed, etc.) is “full”, and it will for sure do, meaning that we in the worst case need to make a novel product, a new platform. This can also happen when we introduce requirements where the solution is affecting all parts (like cyber security most often will) or we will have ripple effects as in the example above, which means that a new top-down systems design, or a re-evaluation, for the whole system for sure is needed. This also means that the longer we had this successful platform, the higher risk is that the way of working has been too decentralized, without preparing for the new platform well in advance. This gives that we do not have any way of working for the top-level systems design, as well as no responsibility, no competences, no capabilities, no experience, no job positions, no tools, etc., since we for a long time have not needed it. This is of course understandable, but will stall any organization. Especially because there is not even someone responsible for the total way of working, or maybe not even the total product. There is therefore no one that can take the decision to take back this top-down approach into the way of working again, that decades ago made the initial successful platform possible.
To be very clear and repeat the above, we below have two scenarios where the top-down approach is definitely not followed, which will generate infinite severe symptoms, unfortunately also discovered very late as explained already above.
- Only the functional requirements are considered, and divided into smaller and smaller pieces, without considering the non-functional requirements. This approach is common for agile at scale software development, and looks like this for novel products, Way of Working – system design on teams level:

Here is apt to add that only add more and more functionality, by choosing the current most important requirement from several different backlogs, will of course for big systems taking long time to implement, give no overview how much code that in the end will be added, how time critical parts of the code are, the bandwidth and speed of the data it needs. Implementation of big systems can take many years, and without systems design the risk taken is enormously high.
With only systems design at the team’s level, there ca never be a proper systems architecture, on the above levels, and which also means that the teams work in their architectural parts like isolated islands. There are neither testing on higher levels mentioned above as well, since the non-functional requirements have not been considered from start. The lack of proper systems design, means lack of proper control of the requirements, which in turn means lack of traceability, etc. Systems design is really about a hypothesis of how to solve all the requirements, where the non-functional requirements are the tricky ones, and a very important part for the system architecture. Systems design means first analysis and then synthesis, where synthesis is integrating and not aggregating, in order to fulfil the requirements (what), i.e., parts can never be validated themselves. All this will of course lead to tremendous inefficiency and low quality, and most probably a product with low performance too, probably it will not work, which of course make an agile approach not useable for products where high safety and security is mandatory. Note, that due to the high complexity inherit in big systems, refactoring will not help us.
- One variant of this is when systems design explicitly is added on top of an agile at scale way of working, due to that the organization understands the need of systems design, which can be the fact when the organization originally is developing hardware products, since it then is obvious that systems design is always needed for novel products. But, even if the systems design is done at earlier levels, it is still too late if it is not done from the top, since the non-functional requirements are still not considered from start (and probably not in the systems design actually done at the team of teams’ level). Then it will look like this for a novel product, Way of Working – system design on team of teams level:

Even if we in this case have systems design on the team of teams’ level, the architectural parts on that layer are still isolated islands. This means that even if the architectural parts on the teams’ level fit together, we still do not know if the whole will work, since we are missing the first two upper levels.
Here is a last picture that shows what will happen when we are missing the transdisciplinary work, and thinking, in an organization. Without the transdisciplinary work, there are only the disciplines that actually can take actions, which they of course will do, but regardless of the What on any level, missing the transdisciplinary work:
![]()
We can see that it is not many similarities with the systems design top-down level per level, i.e. transdisciplinary work, shown in the background. This transdisciplinary work is always needed for systems design, or even planning or release management, which are found in production as well. It is important to point out, that even if we start from the top as in this picture, this is only from the top of each discipline, which does not mean the needed transdisciplinary solutions within in our product development way of working, that we are longing for.
We end this article as we started, with stating how important the ability of systems design is, since reducing transdisciplinary complexity/ complicatedness, is key when we are developing novel products and platforms in any domain; software, hardware, or combinations of hardware and software, as well as building, bridges, etc.
Next article in this series, is about the need of virtual delivery structures in product development.