

To understand why we historically got something called Big Bang integration testing, we need to start somewhat earlier, namely with the, in software development often disreputable Waterfall method.
The Waterfall method was originally used in hardware projects, where the product during the early systems design phase, is divided into modules (often directly mapped to the subsystems in the architecture) with their own functional and non-functional requirements. These modules are designed not only to fit together at the later integration phase to make a full integrated system, but also to fulfil the functional and non-functional system requirements of the system as a unified whole. This is done during the system verification phase. The aim of the systems design phase is to reduce the complexity, and can be done iteratively also on big modules if necessary.
To avoid a Big Bang integration testing (incl. validation and verification) of the full system, hardware projects have since more than half a century used prototypes for the first integration events and of course also for earlier integration testing between modules with (new) complicated interfaces and relationships. The reason for doing this is that even though a systems design has been done properly, knowledge need to be gained in order to continually reduce the complexity. Trying to make the perfect specification is due to complexity not possible, at least not with reasonable time and money spent. Better is to use a few planned prototypes. The more novel the product we are developing is, the more knowledge need to be gained and the more prototyping needed.
Even better at reducing complexity than the prototype thinking (that reduces only transdisciplinary complicatedness) in the Waterfall method, is Lean Product Development. Lean Product Development for hardware (from Toyota, and many other Japanese companies too) takes this a step further, especially when making modular platforms, but also regarding completely new products/systems with high transdisciplinary complexity, see this blog post for a deep-dive. This is achieved by early experimentations using techniques like Set-Based Design, Multiple Concepts and Model-Based Systems Engineering (MBSE), in order to reduce the transdisciplinary complexity for the first systems designs of the wholeness. It is frankly just about reducing the complexity of the wholeness, or the Big Picture of the system you are planning to integrate, by gaining new knowledge of the wholeness, by exploration with experiments, and to do that as early as possible. When the transdisciplinary complexity is reduced to transdisciplinary complicatedness, we can do prototypes like for the Waterfall method.
So, the question is why on earth there is a phenomenon called Big Bang integration testing for us in software development, since hardware development seemed to have worked it out on how to reduce complexity? The reasons for that are for sure plenty, like the many hardware and software differences, but today we will focus on what we in software development have done trying to avoid Big Bang integration testing.
By just looking at the mere number of different integration testing strategies for software development, we can see that we have not been lazy. We have Big Bang, Top-down, Bottom-up, sandwich, incremental, functional incremental and so on. We can divide them into two different types of work package strategies, one is modules, and the other is incremental functionality with end-to-end customer value like in agile software development. When we see modules, we can understand that some kinds of systems design have been made like in hardware, and many times the modules are mapped directly to subsystems in the architecture. Due to the module hierarchy, we can also see that the systems design is made top-down, which means that it is scalable no matter size, even though a big system of course has more complexity, which may require more early experimentation and not only prototypes.
In agile software development, our architecture needs to be done top-down as always in product development, which means that size (or domain) does not matter. Of course, we can also have an agile architecture strategy, where we later fill in the details in the architectural subsystems with micro services for example, or we can even have a strategy where we are adding architectural subsystems gradually, but the architecture is still top-down, i.e., scalable. But, what about the end-to-end incremental work packages, not corresponding to subsystems in the architecture, are they scalable?
If we have a smaller software product, taken care of by one or a few teams, like in a small company, the teams have full control over not only the architecture, but also the overall functional and non-functional requirements on the product, so they can do the systems design, the system integration and the system testing. And if they have not done the systems design properly, due to time to market issues or similar, they refactor their code. This is possible due to the system is small, which makes the complexity low. But what can happen when we are a big company, with a big product, and we have started our agile journey with a few agile teams at first, that now have shown to be successful, and it is time to scale to all software development teams?
The common way is to do a bottom-up scaling, when we are adding more agile teams. An architecture is normally considered top-down, but the wholeness and the top-down approach for reducing complexity with systems design on the whole, is most often neglected in a bottom-up approach. The teams will then work with functionality in the product that has not been part of any systems design, so we are not talking about lack of trust to our great agile teams, they simply have not got the right prerequisites since no one has taken care of the whole first*. The risk is then high that the teams are doing their own gig with functionality that is too loosely coupled, meaning that we are unable to fulfil the requirements of the whole.
There is of course no exact line when refactoring is too risky to lean on and we instead from the beginning definitely need to start with a proper systems design, but there are many indicators like; the system is big and complex and takes many years with many teams to implement, backend is absolutely the biggest part of the system and the backend clearly need to be done, the system will live more than a decade and not only a year and the system has high security which means that high quality is needed, where security all by itself requires systems design. On top of that we can also add that if we are a service company, we are selling our service product and not our software supporting the service, meaning that we already have a working support system. This means that we have considerably lower risk to go out of business, and we will also most probably have a long-lived product, especially for the backend part, which in turn means that a systems design is well invested money. Service companies that can be mentioned are for example banks, insurance companies and all kind of governments, that all of them also need high security.
If the interconnectivity within our system product only had the complexity level of a jigsaw puzzle, only a top-down made architecture would be fine. But, the parts in software products as well as other products, are instead deeply interconnected and related, where the butterfly effect is a good example of what can happen when the systems design has been neglected. To avoid extremely high risk taking, the systems design is therefore always important to start with, no matter of the number of teams involved or size of the product, in order to reach enough details in comparison with the uncertainty of customer acceptance of the product.
This means that without a proper systems design, we are only making a false integration of the parts to the whole, i.e., we are putting the code together by aggregation to a whole. And it does not matter if the parts themselves have a high-quality level. All this is very well summarized by Dr. Russell Ackoff in a speech from 1995 [1]; “The performance of a system depends on how the parts interact, not how they act taken separately.”, or later in the same speech [2]; “Defect management is not an effective mode of management.”, where he is indirectly referring to sub-optimisation.
Beware of that Continuous Integration will not help us here, since only the parts one by one have built-in quality due to a thoroughly systems design per part by the teams. But, that does not at all mean that we have done systems design on the whole per se, also meaning that the whole system product will not have built-in quality. We have escaped the Big Bang integration testing with modules, but instead ended up in Gig Bang integration testing, by practicing false integration in our desire to achieve Continuous Integration.
So, our common answer to avoid Big Bang integration testing for big software products, is definitely not to only make things smaller and smaller and with some Bottom-Up magic and think that the complexity has vanished when we combine the parts to a whole again. No, what happens is only that we have taken gigantic (another apt gig 😉 ) risks. Because, with the absence of systems design, we really have no clue if the parts will fit together to a unified whole, especially not regarding non-functional requirements like performance, error handling, traceability, security, etc. Here is a picture about gig development, that is illustrating implementation of gigs that without any systems design will result in tremendous amount of remaining hidden transdependencies, see this blog post for the meaning of transdependency, hidden transdependency and known interdependencies.
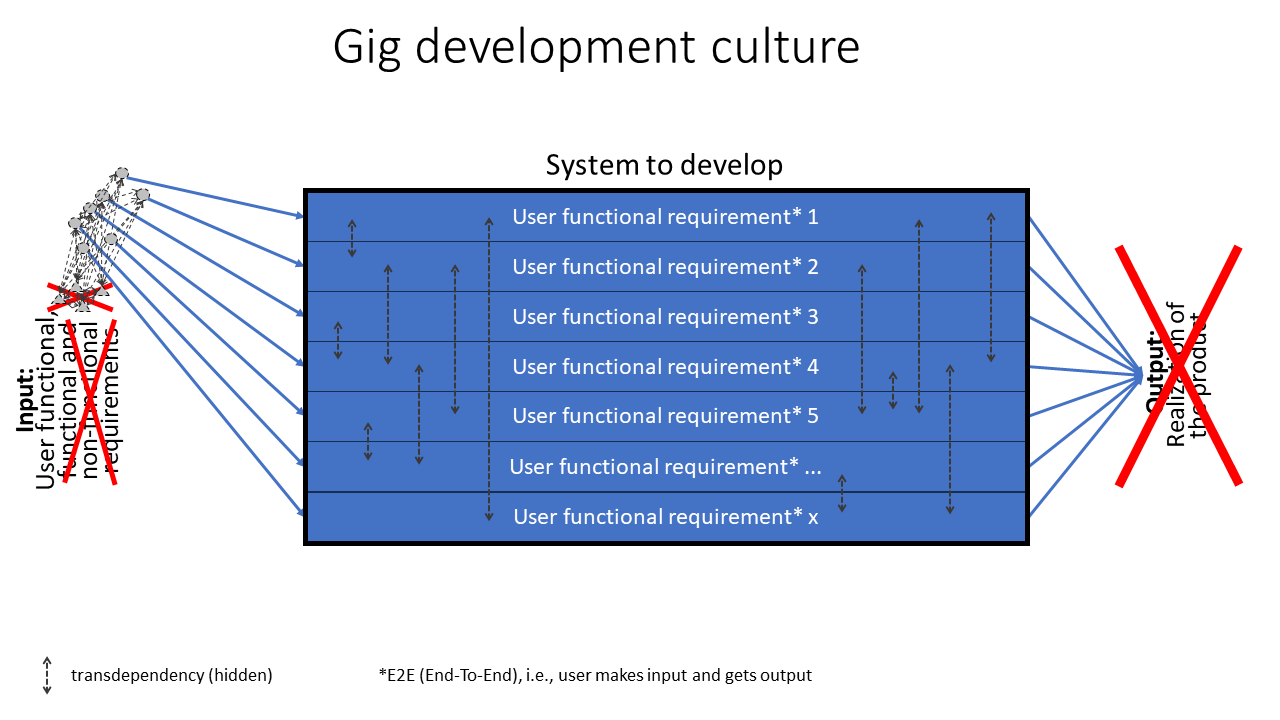
This also means that the Built-in quality strategy that is only focusing on the parts or features that the teams build, is a naïve strategy to get Built-in quality on the whole. And no Continuous Improvement (Lean term: Kaizen) in the world can help us, since it is problem-solving on the whole (Lean term: Jidoka) that is needed. The reason is that we have introduced a lot of symptoms when we neglected the systems design and the root cause is of course to fix the systems design. Continuous Improvement is only a method to improve a standalone, independent, stable and standardized process, not to solve symptoms, which also is impossible, since we then will have the butterfly effect again.
Going back to the bottom-up scaling approach, except for the architecture that is top-down, this means that the non-functional requirements on the whole system most probably has been neglected, which is common in large-scale agile. This in turn means that the parts of the system; subsystems, components, flows, pipelines, or similar have not got their own respective non-functional requirements. This also means that the test environments including testcases and test data, as well as automatic testing for the full system or its parts, have not been considered, since all money instead has been put on Built-in quality, a term from production. This means that we will not be able to find tricky bugs on the total system until our software reaches our customers, which is cumbersome to say the least. This is especially true for safety critical systems and systems in the economic sector, like banks, insurance companies or retirement salary systems, which are systems that must be reliable. Common problems in big systems with many teams working with a Continuous Integration, Built-in quality and bottom-up scaling approach, due to the non-focus on systems design and systems testing, are:
- With features, Continuous Integration and a bottom-up scaling approach, each team integration means that the new code need to work with the existing code. But, when we need to change an interface, we will get a chaos, since the we are back to integration events like for prototypes, meaning we need a systems designer, an integration leader, a coordinator etc. Interface changes can generate tonnes of reactive and non-planned work regarding changes of test cases, leading to unnecessary delays.
- Test systems are often the responsibility of the line and not the responsibility of the initiative/program/project, meaning a very late, reactive and deficient update of the test environment, due to the lack of the system requirements and the initiative/program/project’s low understanding of the test environment, which results in; “this is the way we have done before”, happy testing, manual testing and only looking on already existing “systems” within the new (updated) system solution.
- Because of no long-term planning for the test environment exists, new code to be added can take 2 days to implement and test locally, but the test environment for testing a little bigger part, may take weeks to implement. This delay is not in the plan, which often lead to a deficient solution in the code, to avoid the delay. The consequences of this deficient solution will later generate a massive extra re-development, when the system is extended with new functionality. But, without a proper system test environment…you get it.
- Very late and reactive understanding if new test environments are needed, for parts or for the whole, which is especially valid for totally new product development.
- We will have test environments that all teams need for their specific tests of their parts with their own test cases and test data that can alter the test environment, meaning that they will block each other more and more, the closer we come to a release. Once again, we need an integration leader, coordinator or similar to increase the efficiency and reduce the friction between the teams.
- Refactoring will not help due to the extremely higher complexity compared to a small system with a few teams, and to rebuild the system with a systems design, as the only option, is a very time-consuming and expensive.
- Refactoring parts in order to try to fix a neglected systems design, only lead to suboptimization, since Kaizen cannot be used, when Jidoka is needed for finding the root cause (the neglected systems design)
- Lacking automated tests on the whole system makes bug fixing or even local refactoring a nightmare, since no one wants to risk the system to stop due to hidden bugs are revealed somewhere else
- The validation done of the parts by internal customers during the development of the system at for example system demos, but actually no released functionality, are due to the lack of a proper system test environment, only considering a specific part of the product, but not if the system itself has been done correct. This is a typical example of false integration, since we only consider the validation and verification of the parts (that never have been part of a systems design), not the whole system. For the validation and its business value, it is to some degree possible to accumulate the functionality to a whole, but for verification it will be a total flaw if a proper systems design has not been done from the beginning. To summarize this, it means that the business value shown during system demos is not worth anything, if the system tests on the whole showing that the system has also been built correct, hasn’t been done before the system demos.
So, now when have we seen many different attempts that we have done in agile software development, the first step is to understand why we needed to make the attempts since hardware did not need that in the first place. Context dependence is king as always in complex systems and we can also see the necessity of top-down thinking, when the complexity is increasing, so we need to find out more about them both and their relationship. The second step is then to see if we can find an overall method, that with some different flavours can cover different contexts, which is of course easier said than done**, but we need to give it a perseverant try.
The coming blog posts will dig further into this matter, since we really need to do something about it. And that will most probably mean that we need to change our patterns of thought, so we can think anew to be able to act anew. Before that some other important and related blog posts about verification and validation, hypothesis, innovations, will be presented, since they are key to understand before digging deeper into what we can do about it.
C u soon again.
*This has nothing to do with an original agile method like Scrum or Kanban, it is the scaling that is done wrongly bottom-up, when it always needs to be done top-down in bigger systems, hardware, software, buildings, to mention a few.
**there are tremendous many parameters to take care of that sets the context like; complexity, uncertainty, size of product, size of organisation, competence, experience, back-end, UX, etc.
References:
[1] Ackoff, Dr. Russell Lincoln. Speech. “Systems-Based Improvement, Pt 1.”, Lecture given at the College of Business Administration at the University of Cincinnati on May 2, 1995.
Link copied 2018-10-27. At 15:03.
Russell Ackoff – Systems-Based Improvement, Pt 1 – YouTube
[2] Ackoff, Dr. Russell Lincoln. Speech. “Systems-Based Improvement, Pt 2.”, Lecture given at the College of Business Administration at the University of Cincinnati on May 2, 1995.
Link copied 2018-10-27. At 10:58.
Russell Ackoff – Systems-Based Improvement, Pt 2 – YouTube